浏览器是再熟悉不过的东西了,几乎每个人用过,比如 Chrome、FireFox、Safari,尤其是我们程序员,可谓开发最强辅助,摸鱼最好的伴侣。
浏览器能干的事儿,无头浏览器都能干,而且很多时候比标准浏览器还要更好 用,而且能实现一些很好玩儿的功能,我们能借助无头浏览器比肩标准浏览器强大的功能,而且又能灵活的用程序控制的特性,做出一些很有意思的产品功能来,稍后我们细说。
关于浏览器还有一个很好玩儿的梗,对于一些对计算机、对互联网不太了解的同学,你跟他说浏览器,他/她就默认是百度了,因为好多小白的浏览器都设置了百度为默认页面。所以很多小白将浏览器和搜索引擎(99%是百度)划等号了。

浏览器里我百分之99的时间都是用 Chrome,不过有一说一,这玩意是真耗内存,我基本上是十几、二十几个的 tab 开着,再加上几个 IDEA 进程,16G 的内存根本就不够耗的。
以 Chrome 浏览器为例,Chrome 由以下几部分组成:
Chrome 浏览器光源码就有十几个G,2000多万行代码,可见,要实现一个功能完善的浏览器是一项浩大的工程。
无头浏览器(Headless Browser)是一种浏览器程序,没有图形用户界面(GUI),但能够执行与普通浏览器相似的功能。无头浏览器能够加载和解析网页,执行JavaScript代码,处理网页事件,并提供对DOM(文档对象模型)的访问和操作能力。
与传统浏览器相比,无头浏览器的主要区别在于其没有可见的窗口或用户界面。这使得它在后台运行时,不会显示实际的浏览器窗口,从而节省了系统资源,并且可以更高效地执行自动化任务。
常见的无头浏览器包括Headless Chrome(Chrome的无头模式)、PhantomJS、Puppeteer(基于Chrome的无头浏览器库)等。它们提供了编程接口,使开发者能够通过代码自动化控制和操作浏览器行为。
无头浏览器其实就是看不见的浏览器,所有的操作都要通过代码调用 API 来控制,所以浏览器能干的事儿,无头浏览器都能干,而且很多事儿做起来比标准的浏览器更简单。
我举几个常用的功能来说明一下无头浏览器的主要使用场景
开篇就说了使用无头浏览器可以实现一些好玩儿的功能,这些功能别看不大,但是使用场景还是很多的,有些开发者就是抓住这些小功能,开发出好用的产品,运气好的话还能赚到钱,尤其是在国外市场。(在国内做收费的产品确实不容易赚到钱)
下面我们就来介绍两个好玩儿而且有用的功能。
前面的自动化测试、服务端渲染就不说了。
自动化测试太专业了,一般用户用不到,只有开发者或者测试工程师用。
服务端渲染使用无头浏览器确实没必要,因为有太多成熟的方案了,连 React 都有服务端渲染的能力(RSC)。
我们可能见过一些网站提供下载文字卡片或者图文卡片的功能。比如读到一段想要分享的内容,选中之后将文本端所在的区域生成一张图片。

其实就是通过调用浏览器自身的 API page.screenshot,可以对整个页面或者选定的区域生成图片。
通过这个方法,我们可以做一个浏览器插件,用户选定某个区域后,直接生成对应的图片。这类功能在手机APP上很常见,在浏览器上一搬的网站都不提供。
说到这儿好像和无头浏览器都没什么关系吧,这都是标准浏览器中做的事儿,用户已经打开了页面,在浏览器上操作自己看到的内容,顺理成章。
但是如果这个操作是批量的呢,或者是在后台静默完成的情况呢?
那就需要无头浏览器来出手了,无头浏览器虽然没有操作界面,但是也具备绘制引擎的完整功能,仍然可以生成图像,利用这个功能,就可以批量的、静默生成图像了,并且可以截取完整的网页或者部分区域。
Puppeteer 是无头浏览器中的佼佼者,提供了简单好用的 API ,不过是 nodejs 版的。
如果是用 Java 开发的话,有一个替代品,叫做 Jvppeteer,提供了和 Puppeteer 几乎一模一样的 API。
下面这段代码就展示了如何用 Jvppeteer 来实现网页的截图。
下面这个方法是对整个网页进行截图,只需要给定网页 url 和 最终的图片路径就可以了。
因涉及一些执行语句,禁止写入,请联系客服获取
一个自动滚屏的方法。
虽然可以监听页面上的事件通知,比如 domcontentloaded,文档加载完成的通知,但是很多时候并不能监听到网页上的所有元素都加载完成了。对于那些滚动加载的页面,可以用这种方式模拟完全加载,加载完成之后再进行操作就可以了。
使用自动滚屏的操作,可以模拟我们人为的在界面上下拉滚动条的操作,随着滚动条的下拉,页面上的元素会自然的加载,不管是同步的还有延迟异步的,比如图片、图表等。
因涉及一些执行语句,禁止写入,请联系客服获取
调用截图方法截图,这里是对一篇公众号文章进行整个网页的截图。
因涉及一些执行语句,禁止写入,请联系客服获取
或者也可以截取页面中的部分区域,比如某篇文章的正文部分,下面这个方法是截图一个博客文章的正文部分。
因涉及一些执行语句,禁止写入,请联系客服获取
调用方式:
因涉及一些执行语句,禁止写入,请联系客服获取
最后的效果是这样的,可以达到很清晰的效果。
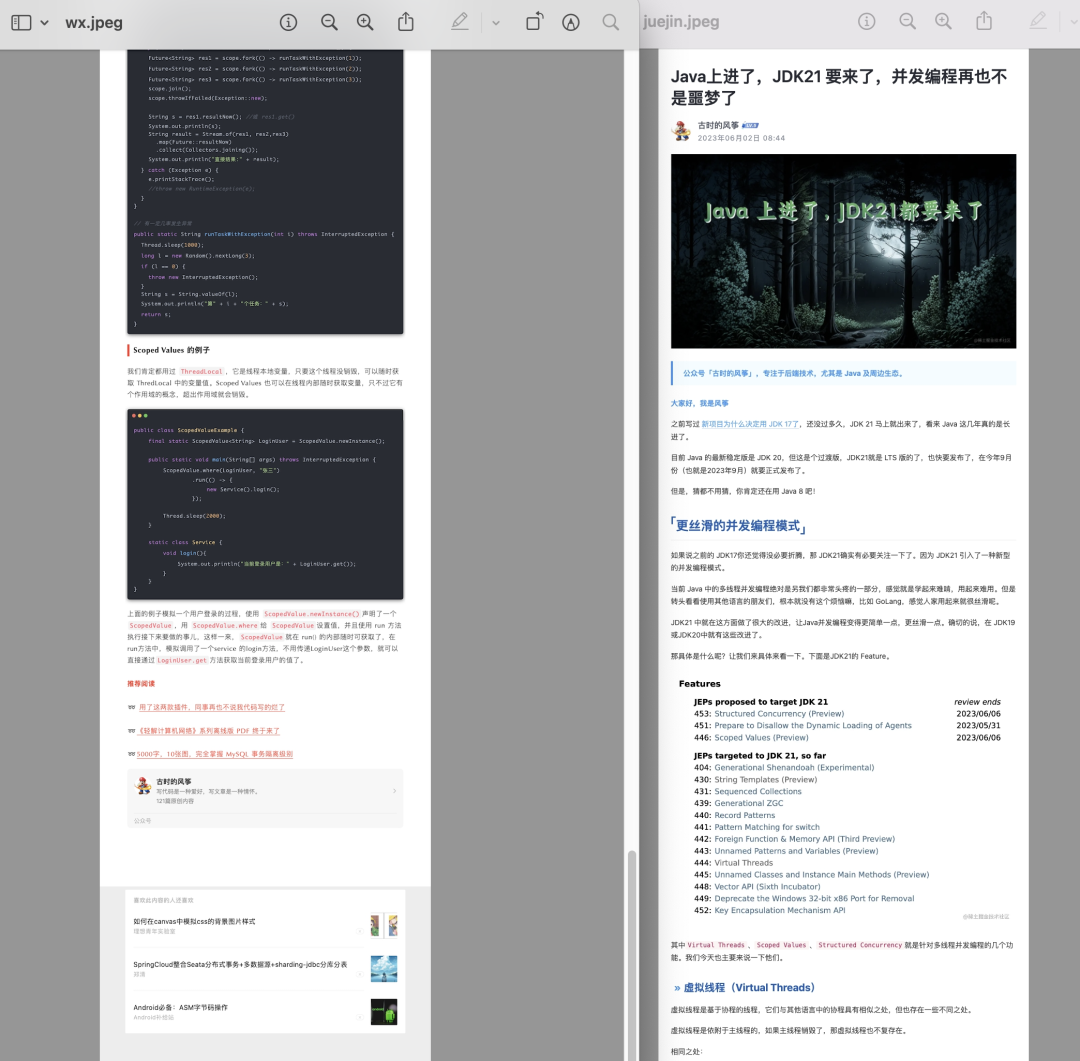
这个功能可太有用了,可以把一些网页转成离线版的文档。有人说直接保存网页不就行了,除了程序员,大部分人还是更能直接读 PDF ,而不会用离线存储的网页。
我们可以在浏览器上使用浏览器的「打印」功能,用来将网页转换成 PDF 格式。
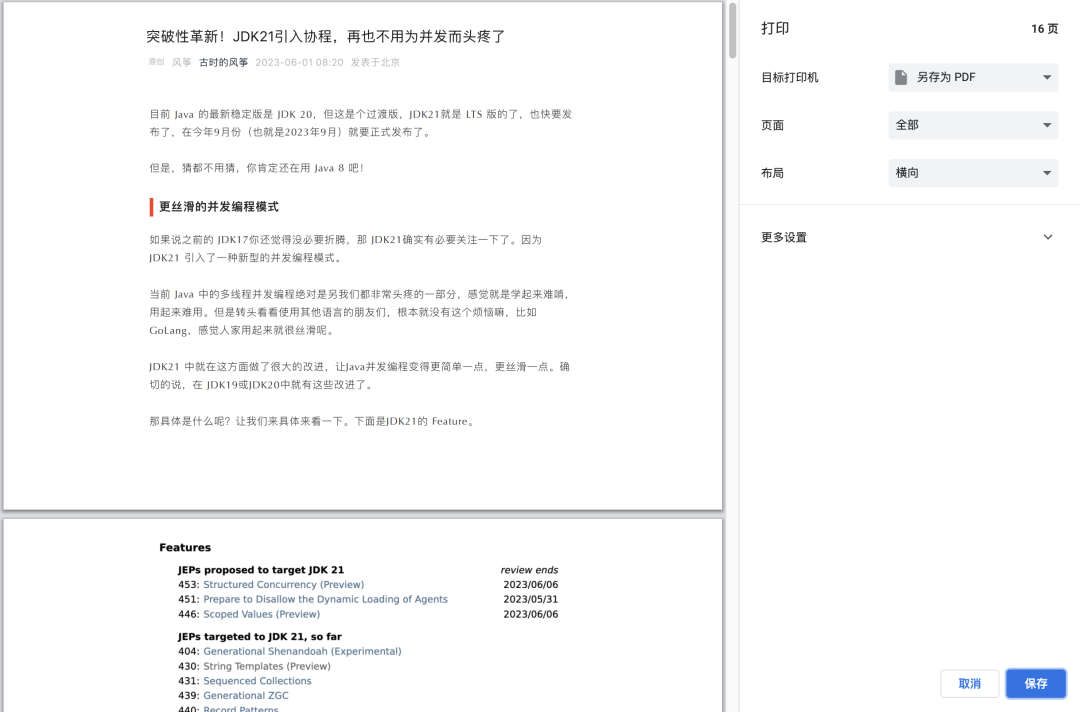
但这是直接在页面上操作,如果是批量操作呢,比如想把一个专栏的所有文章都生成 PDF呢,就可以用无头浏览器来做了。
有的同学说,用其他的库也可以呀,Java 里面有很多生成 PDF 的开源库,可以把 HTML 转成 PDF,比如Apache PDFBox、IText 等,但是这些库应对一般的场景还行,对于那种页面上有延迟加载的图表啊、图片啊、脚本之类的就束手无策了。
而无头浏览器就可以,你可以监听页面加载完成的事件,可以模拟操作,主动触发页面加载,甚至还可以在页面中添加自定义的样式、脚本等,让生成的 PDF 更加完整、美观。
下面这个方法演示了如何将一个网页转成 PDF 。
因涉及一些执行语句,禁止写入,请联系客服获取
调用生成 PDF 的方法,将一个微信公众号文章转成 PDF。
因涉及一些执行语句,禁止写入,请联系客服获取
最终的效果,很清晰,样式都在,基本和页面一模一样。
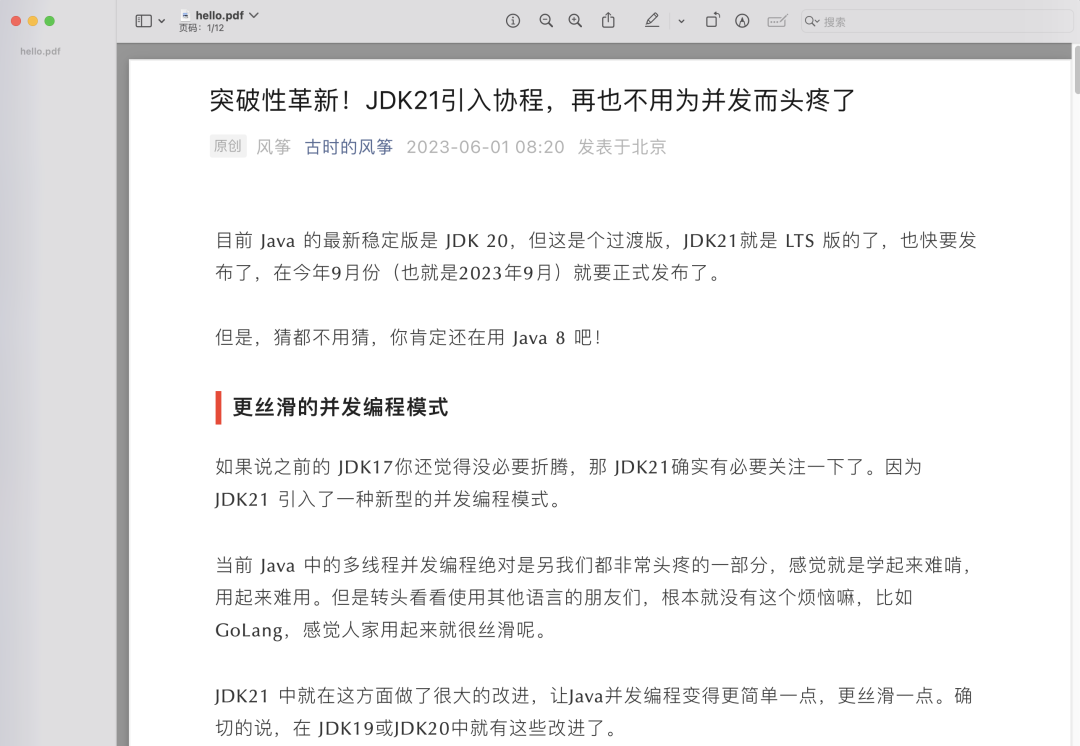
本文就是愿天堂没有BUG给大家分享的内容,大家有收获的话可以分享下,想学习更多的话可以到微信公众号里找我,我等你哦。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

