from __future__ import print_functionimport osimport timeimport argparseimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.optim.lr_scheduler import StepLRimport torch.distributed as dist
def init_distributed_mode(args):'''initilize DDP'''if "RANK" in os.environ and "WORLD_SIZE" in os.environ:args.rank = int(os.environ["RANK"])args.world_size = int(os.environ["WORLD_SIZE"])args.gpu = int(os.environ["LOCAL_RANK"])elif "SLURM_PROCID" in os.environ:args.rank = int(os.environ["SLURM_PROCID"])args.gpu = args.rank % torch.cuda.device_count()elif hasattr(args, "rank"):passelse:print("Not using distributed mode")args.distributed = Falsereturnargs.distributed = True
torch.cuda.set_device(args.gpu)args.dist_backend = "nccl"# args.dist_backend = "gloo"print(f"| distributed init (rank {args.rank}): {args.dist_url}, local rank:{args.gpu}, world size:{args.world_size}", flush=True)dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url, world_size=args.world_size, rank=args.rank)class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout(0.25)self.dropout2 = nn.Dropout(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)output = F.log_softmax(x, dim=1)return output
def train(args, model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if args.distributed:if dist.get_rank() == 0:if batch_idx % args.log_interval == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, dist.get_world_size() * batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))else:if batch_idx % args.log_interval == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))if args.dry_run:breakdef test(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
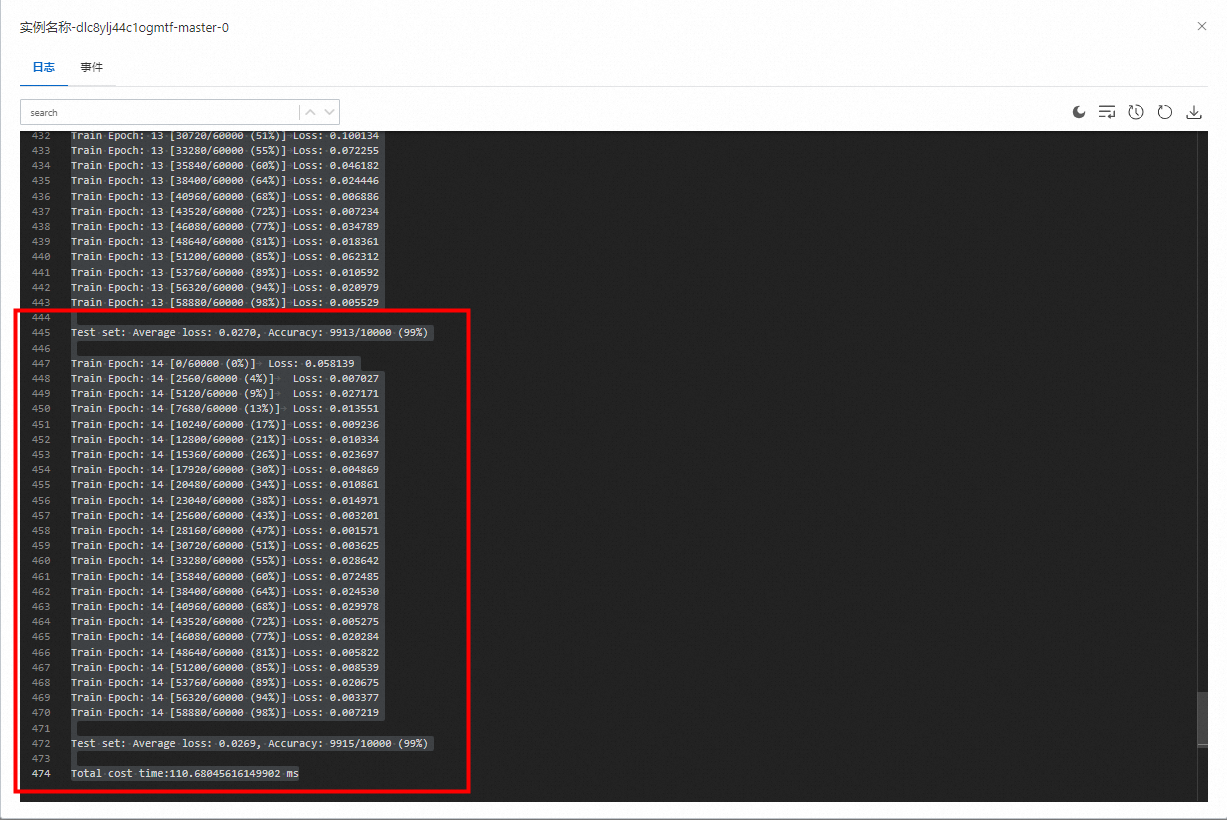
correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))def main():# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')parser.add_argument('--batch-size', type=int, default=64, metavar='N',help='input batch size for training (default: 64)')parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',help='input batch size for testing (default: 1000)')parser.add_argument('--epochs', type=int, default=14, metavar='N',help='number of epochs to train (default: 14)')parser.add_argument('--lr', type=float, default=1.0, metavar='LR',help='learning rate (default: 1.0)')parser.add_argument('--gamma', type=float, default=0.7, metavar='M',help='Learning rate step gamma (default: 0.7)')parser.add_argument('--no-cuda', action='store_true', default=False,help='disables CUDA training')parser.add_argument('--dry-run', action='store_true', default=False,help='quickly check a single pass')parser.add_argument('--seed', type=int, default=1, metavar='S',help='random seed (default: 1)')parser.add_argument('--log-interval', type=int, default=10, metavar='N',help='how many batches to wait before logging training status')parser.add_argument('--save-model', action='store_true', default=False,help='For Saving the current Model')parser.add_argument('--local_rank', type=int, help='local rank, will passed by ddp')parser.add_argument("--world-size", default=1, type=int, help="number of distributed processes")parser.add_argument("--dist-url", default="env://", type=str, help="url used to set up distributed training")args = parser.parse_args()use_cuda = not args.no_cuda and torch.cuda.is_available()init_distributed_mode(args)torch.manual_seed(args.seed)device = torch.device("cuda" if use_cuda else "cpu")train_kwargs = { 'batch_size': args.batch_size}test_kwargs = { 'batch_size': args.test_batch_size}if use_cuda:cuda_kwargs = { 'num_workers': 1, 'pin_memory': True, }train_kwargs.update(cuda_kwargs)test_kwargs.update(cuda_kwargs)transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])dataset_train = datasets.MNIST('./data', train=True, download=True, transform=transform)dataset_val = datasets.MNIST('./data', train=False, transform=transform)if args.distributed:train_sampler = torch.utils.data.distributed.DistributedSampler(dataset_train, shuffle=True)else:train_sampler = torch.utils.data.RandomSampler(dataset_train)test_sampler = torch.utils.data.SequentialSampler(dataset_val)train_loader = torch.utils.data.DataLoader(dataset_train, sampler = train_sampler, **train_kwargs)test_loader = torch.utils.data.DataLoader(dataset_val, sampler = test_sampler, **test_kwargs)model = Net().to(device)model_without_ddp = modelif args.distributed:model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])model_without_ddp = model.module
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)for epoch in range(1, args.epochs + 1):if args.distributed:train_sampler.set_epoch(epoch)train(args, model, device, train_loader, optimizer, epoch)if args.distributed:# Only run validation on GPU 0 process, for simplity, so we do not run validation on multi gpu.if dist.get_rank() == 0:test(model_without_ddp, device, test_loader)else:test(model, device, test_loader)scheduler.step()if args.save_model:if args.distributed:if dist.get_rank() == 0:# only save model on GPU0 process.torch.save(model.state_dict(), f"mnist_cnn.pt")else:torch.save(model.state_dict(), f"mnist_cnn_.pt")if __name__ == '__main__':start = time.time()main()print(f'Total cost time:{time.time() - start} ms')获取公网下载地址:https://*****.oss-cn-hangzhou.aliyuncs.com/mnist-ddp.py
如果有配置数据源nas等,也可以直接将文件上传到nas中
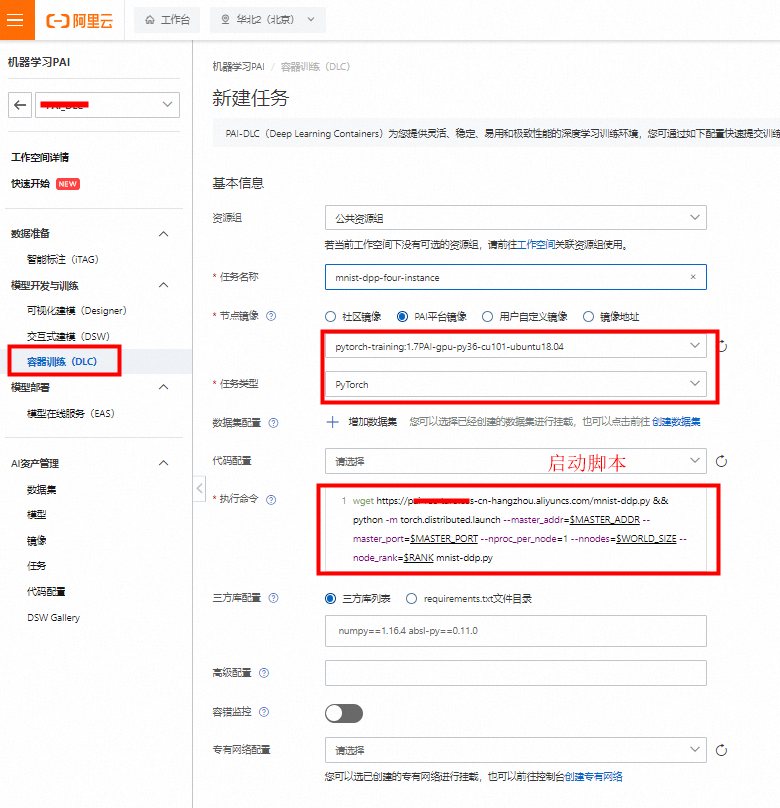
wget https://********.oss-cn-hangzhou.aliyuncs.com/mnist-ddp.py && python -m torch.distributed.launch --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT --nproc_per_node=1 --nnodes=$WORLD_SIZE --node_rank=$RANK mnist-ddp.py
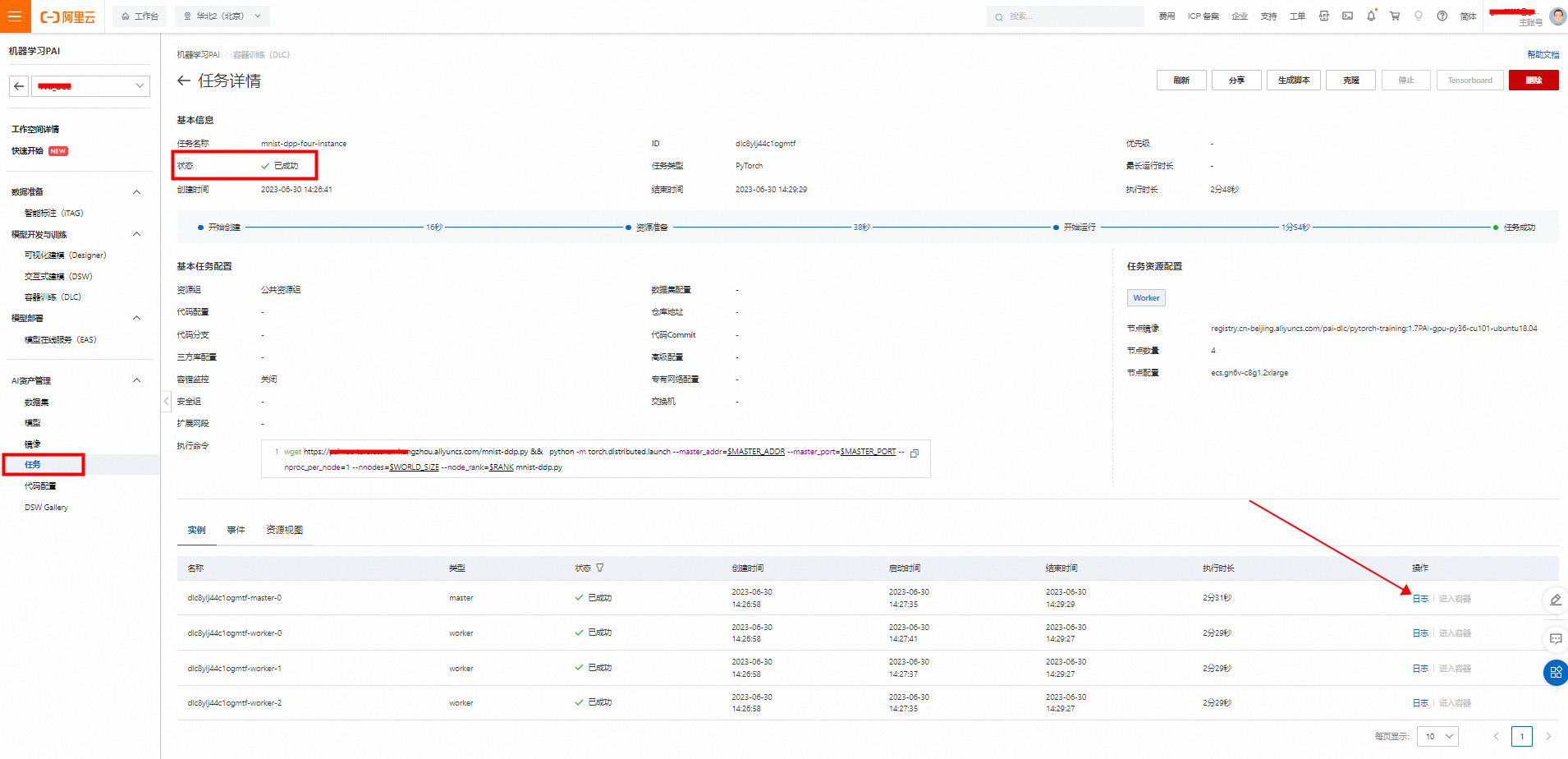
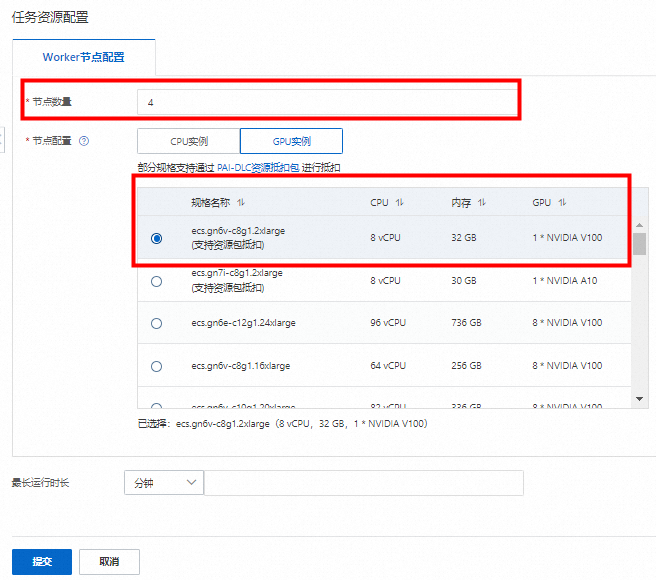
提交分布式DLC任务
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

