
本文主要介绍了 StableDiffusion在图片生成上的内容,然后详细说明了StableDiffusion 的主要术语和参数,并探讨了如何使用 prompt 和高级技巧(如图像修复、训练自定义模型和图像编辑)来生成高质量的图片。

Stable Diffusion是一种潜在的文本到图像扩散模型,能够生成逼真的图像,只需任何文本输入,就可以自主自由创造漂亮的图像,使众多不会拍照的人在几秒钟内创造出惊人的图片。StableDiffusion可以生成不同的图片风格,比如:Anime 动画,realistic 写实,Landscape 风景,Fantasy 奇幻,Artistic 艺术。 还有很多其他的风格,都可以在网上看到。
有一些图示来直观理解StableDiffusion,比较深奥,不过多解释:
https://zhuanlan.zhihu.com/p/599887666
https://stable-diffusion-art.com/models/
网上可以下载到的StableDiffusion模型非常多。只需要记得这些都是SD模型的微调版本即可,这些不同版本的StableDiffusion模型都是基于相同的算法和原理,并且都可以用于生成高质量的图像、音频、视频等数据。具体选择哪个版本取决于应用场景和具体需求。
以下是常见模型,以及说明:

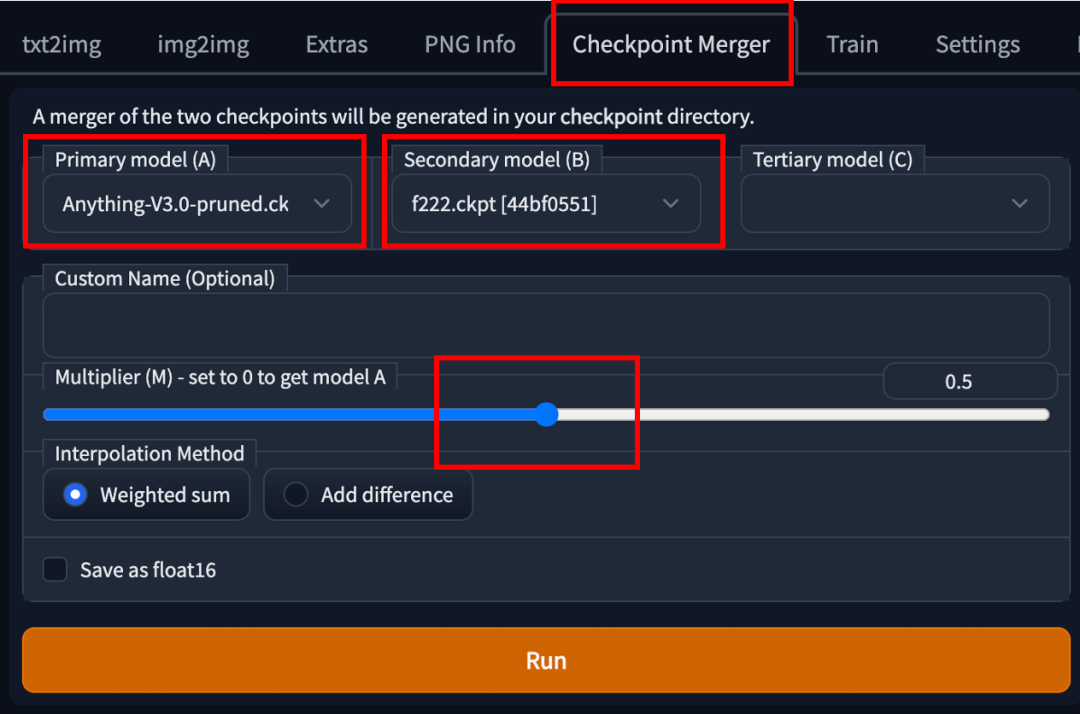
也可以自己做模型的合并,在StableDiffusion的GUI界面如下操作即可:
ControlNet是一种稳定的扩散模型,可以复制作品和人体姿势。想要使用的话再扩展中安装sd-webui-controlnet扩展即可。
正常情况下我们想要控制人物的姿势是十分困难的,并且姿势随机,而ControlNet解决了这个问题。它强大而多功能,可以与任何扩散模型一起使用。
主要作用:
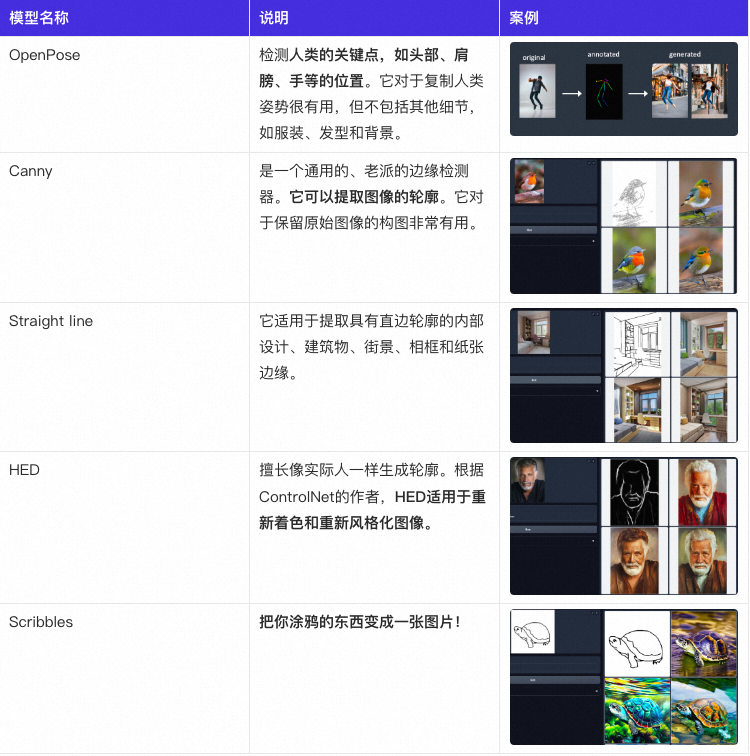
可用的模型以及说明:
不同抽样算法的生成时间对比: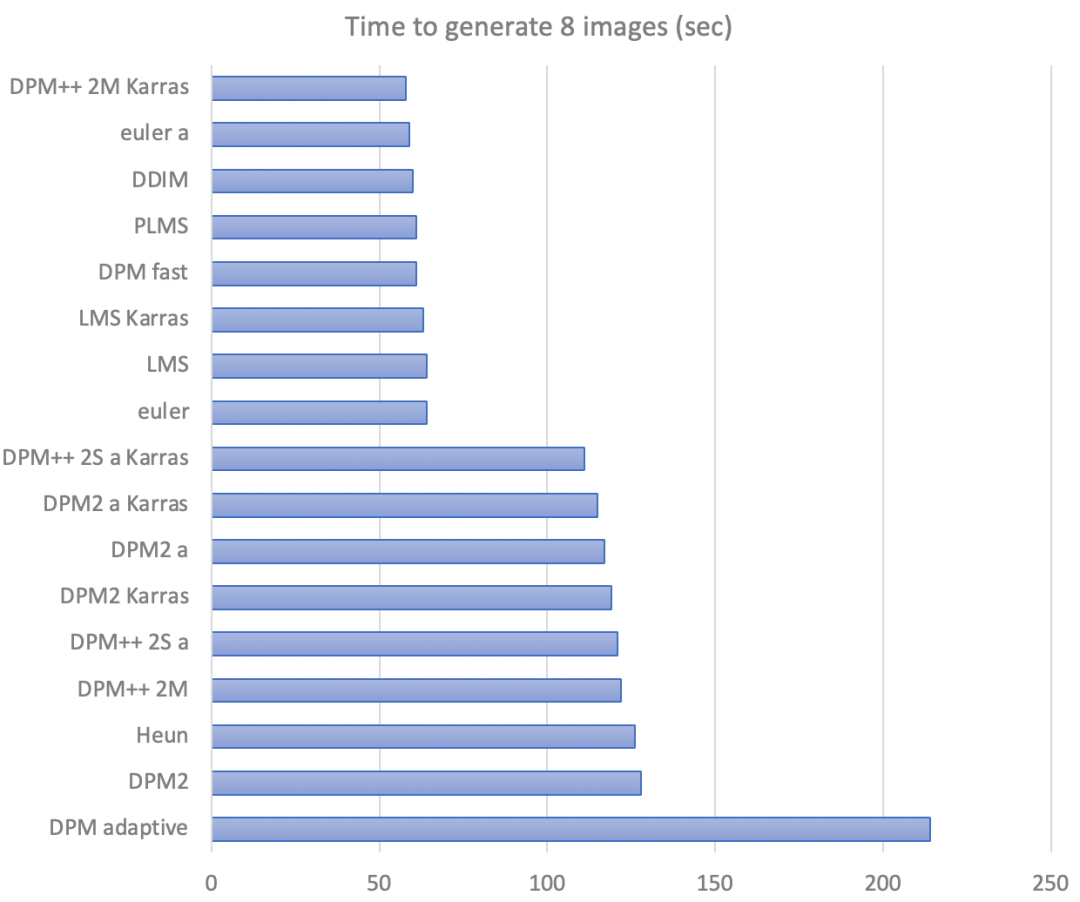
使用不同的抽样算法生成的图片:
a busy city street in a modern city

https://stable-diffusion-art.com/know-these-important-parameters-for-stunning-ai-images/#Sampling_methods

在StableDiffusion中,"prompt"是指为GPT模型提供输入的文本段落或句子。它是用来引导模型生成有意义、准确的响应的关键因素之一。
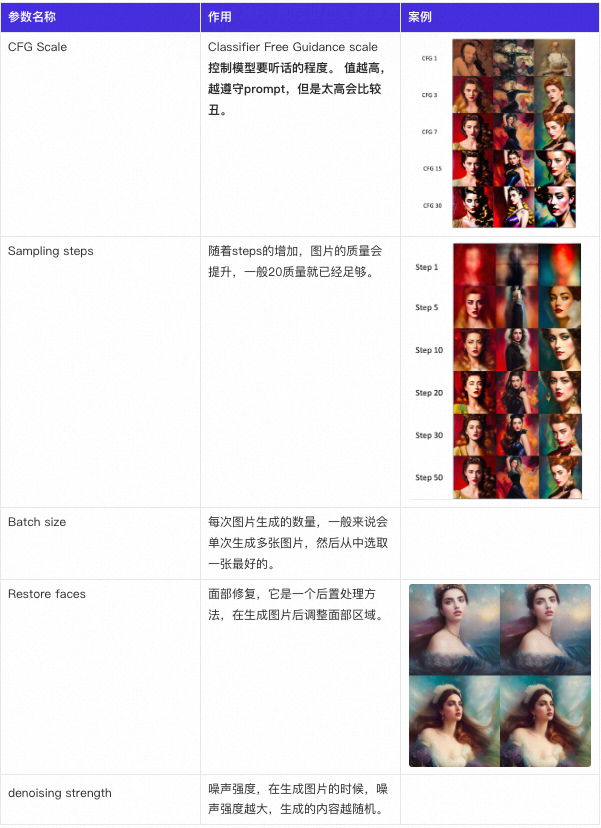
同时可以考虑满足以下的条件:
如果不确定要用什么风格,可以去下面的两个地址搜一下对应的风格

使用()增加权重,使用[]降低权重;

a (word) - 将对单词的权重增加1.1倍
a ((word)) - 将对单词的权重增加1.21倍(= 1.1 * 1.1)
a [word] - 将对单词的权重减少1.1倍
a (word:1.5) - 将对单词的权重增加1.5倍
a (word:0.25) - 将对单词的权重减少4倍(= 1 / 0.25)
a \(word\) - 在提示中使用字面上的()字符,转义,不使用权重
prompt也可以从某个点位开始考虑生成指定的内容:
[from:to:when]
示例:a [fantasy:cyberpunk:16] landscape
另外一种语法:[cow|horse] in a field
第1步,提示是“cow”。第2步是“horse”。第3步是“cow”,以此类推。
更多精彩内容,欢迎观看:
探索 StableDiffusion:生成高质量图片学习及应用(中):
https://developer.leiyu.cn/article/1263238?groupCode=taobaotech
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

