< 返回新闻公共列表
MySQL的性能优化
发布时间:2023-06-26 14:00:10
MySQL的性能优化
- 客户端->服务端->语法解析->生成计划->执行计划->返回结果
- 在MySQL的整个执行流程中,一条SQL的整体响应时间包括但不限于以下时间
- 网络I/O传输时间
- CPU计算时间
- 计划统计时间、计划执行时间
- 锁的互斥等待时间
- 操作系统上下文切换时间、系统调用时间
- 操作系统内存不足的I/O时间
- ......等等
对于SQL的优化,无论是什么数据库都是基于以上的方面进行优化
- 数据库是否检索了大量不需要的数据(如行、列)
- 增加了大量I/O,CPU的计算,内存资源,网络开销
- 查询了不需要的记录(使用limit优化)
- 返回列的数目过多(指定返回的列名,而不使用*)
- 查询了重复的数据(适当使用缓存)
- 数据库是否分析、计算了大量不需要的数据
- 响应时间:避免I/O等待、锁等待
- 扫描行数与返回行数:避免从大量数据中检索出极少的数据(explain分析)
- 扫描行数与访问类型:避免访问一行的数据代价过高(explain分析)
- 对于以上的优化方式有三种
- 使用覆盖索引(减少回表次数)
- 改变表结构(减少无用连接)
- 重写复杂的SQL语句(能够让优化器优化)
- 明确一点:MySQL对于连接的建立、关闭十分的轻
- 一个人做事很难办,那就多带几个人干(分而治之)
- 分片查询;比如说按照时间分片检索,而不是一次性检索全部
- SQL分解;比如将大部分JOIN的查询,分解为几条简单的查询
- 如图:
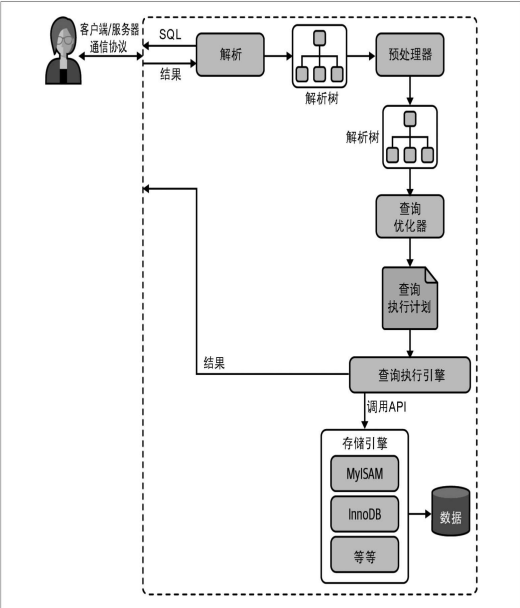
- MySQL的通信协议是半双工的;这意味着在一个时间点只能发或者收
- 因此,为了防止数据过多导致客户端等待过久,一般采用分页(limit)
- 如果说MySQL认为SQL合法,就会由优化器将SQL转化为不同的执行计划
- MySQL的优化器大部分情况是基于成本进行评估的(全文搜索是个例外)
- 重新定义表的连接顺序(优先选择代价最小的执行计划)
- 外连接转化为内连接
- 代数转换变换规则(5=5 and a<5)会变成(a<5)
- 优化COUNT(),MIN(),MAX();
- 如MIN()将直接指向B-Tree最左边,MAX()将指向B-Tree最右边;时间复杂度为常数级
- 预估并且转化为常数表达式(不理解?)
- 覆盖索引扫描(索引列包含查询中需要使用的列)
- 子查询优化
- 提前终止查询(limit,当满足条件时、或者不满足一个条件时)
- 等值传播(指一个列的条件能够传递到另一个列)
- IN()与OR的比较;IN()通过二分查找O(logN),OR普通遍历O(N)
- 排序成本极高,避免对大数据进行排序
- 当不能使用索引排序时,(MySQL会进行排序,小数据时在内存(排序缓冲区),大数据时先分块在排序最后合并)(file sort)
- 两次传输排序:读取行指针以及待排序列先进行排序,然后根据结果读取数据行(在第二个阶段会产生大量的随机I/O,因为第一个阶段使得不在数据有序)
- 一次传输排序:先读取全部数据,然后在进行排序;这种方式会消耗等多的排序缓冲区,产生更多次数的分块、合并操作
- COUNT():返回包含NULL的行数;(**所有的优化前提是COUNT()不包含任何的GROUP BY,WHERE)
- 优化措施:innodb会使用最小的非聚簇索引降低成本
- 优化措施:innodb会认为COUNT(*)是统计行数,而跳过所有列匹配
- 优化措施:MyISAM将所有的行数目记录下来了,直接返回;MyISAM采用表级锁,不会出现数据一致性问题,而innodb采用行级锁,会产生一致性问题,所以不能采用计数策略
- COUNT(COLUMN NAME):这是统计某个列的值不为空的数目
- 性能比较:COUNT(*)优于COUNT(COLUMN NAME)
- 对于JOIN ON或者JOIN USING而言,尽量保证参与计算的列都包含索引,且GROUP BY以及ORDER BY都只涉及一个列
- limit offset优化
- 尽可能使用覆盖索引扫描,而不是扫描所有的行(如下:)
- 通过检索索引在不访问行的情况下检索更少的数据
-- 普通写法
select id, name
from user
order by id
limit 50,5;
-- 优化写法
select id, name
from user
inner join
(select id, name
from user
order by id
limit 50,5) as userT using (id);
- 如果对数据没有去重需求,则一般使用UNION ALL,因为UNION会为临时表添加DISTINCT选项
- UNION:去重
- UNION ALL:不去重

