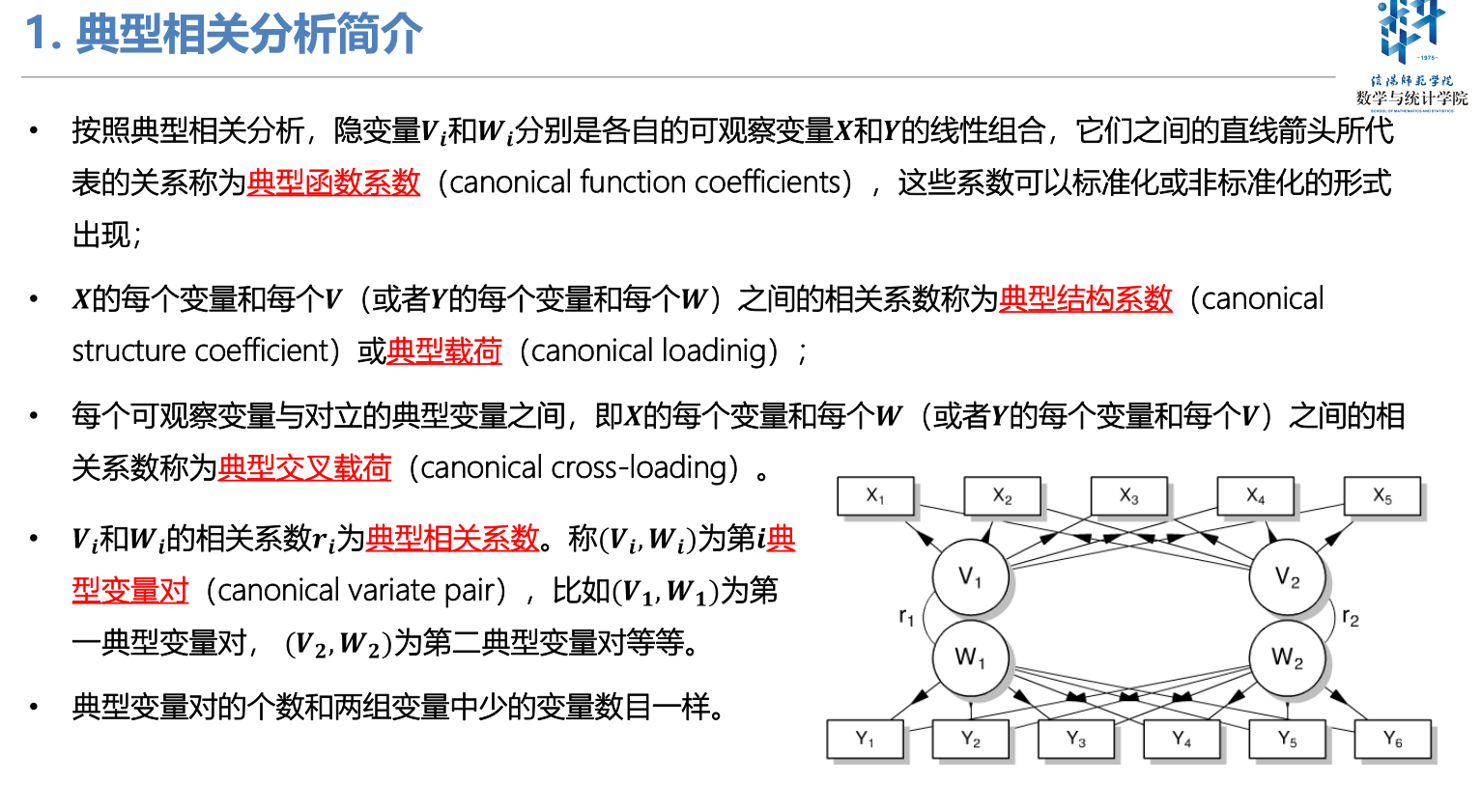
典型相关分析是研究两个多变量(向量)之间之间的线性相关关系,能够揭示出两组变量之间的内在联系。
在一元统计分析中,用相关系数来衡量两个随机变量的线性相关关系,用复相关系数研究一个随机变量与多个随机变量的线性相关关系。然而,这些方法均无法用于研究两组变量之间的相关关系,于是提出了CCA(典型相关分析)。
它将一组变量与另一组变量之间单变量的多重线性相关性研究,转换为少数几对综合变量之间的简单线性相关性的研究,并且这少数几对变量所包含的线性相关性的信息几乎覆盖了原变量组所包含的全部相应信息。
联系
无论是典型相关分析还是主成分分析,都是线性分析的范畴,一组变量的典型变量和其主成分都是经过线性变换,通过计算矩阵的特征值与特征向量得出的。
区别
主成分分析中只涉及一组变量的相互依赖关系,而典型相关则扩展到了两组变量之间的相互依赖的关系之中,度量了这两组变量之间联系的强度。










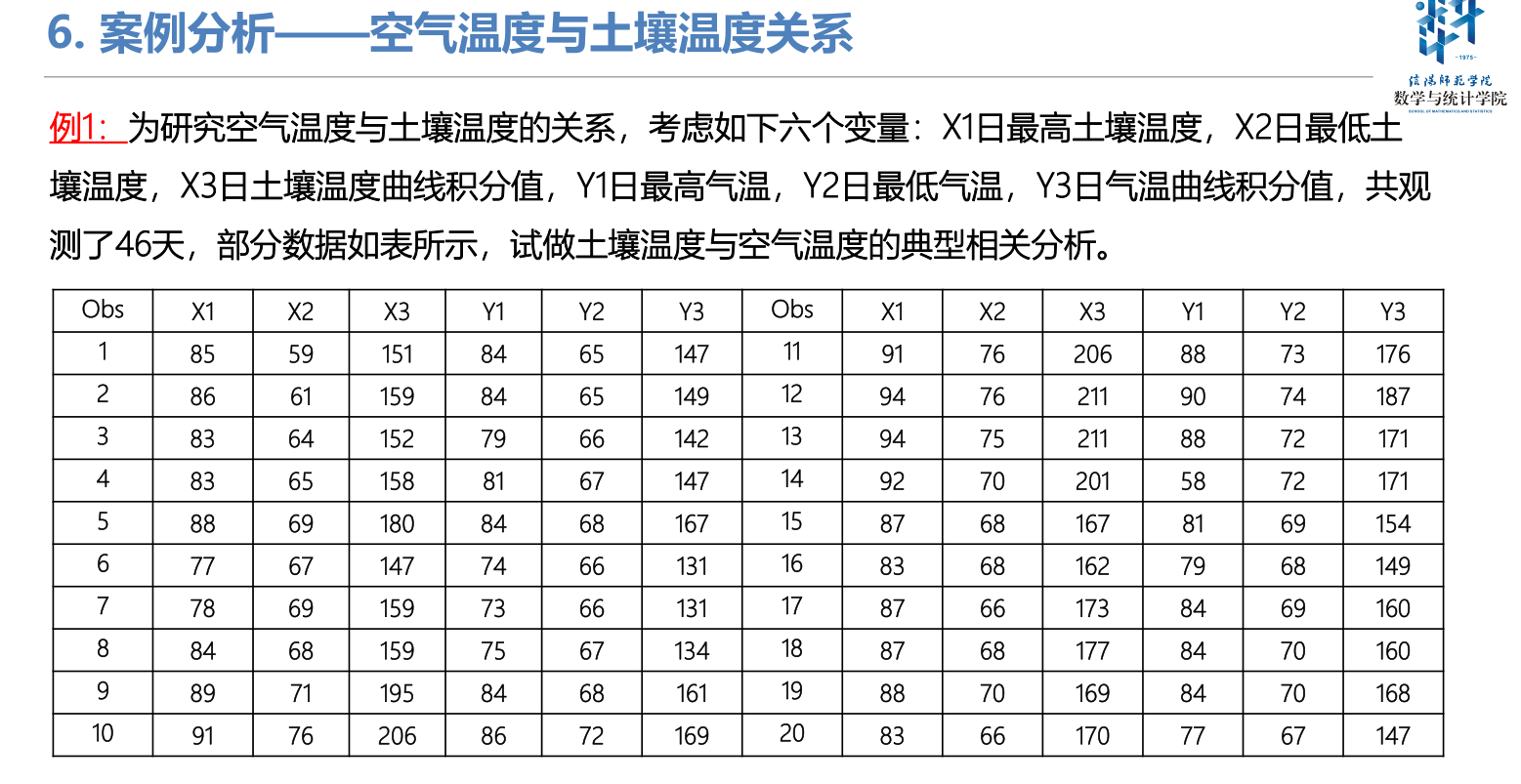
%加载数据 load(data.mat) xlsread('air-soil.xlsx')
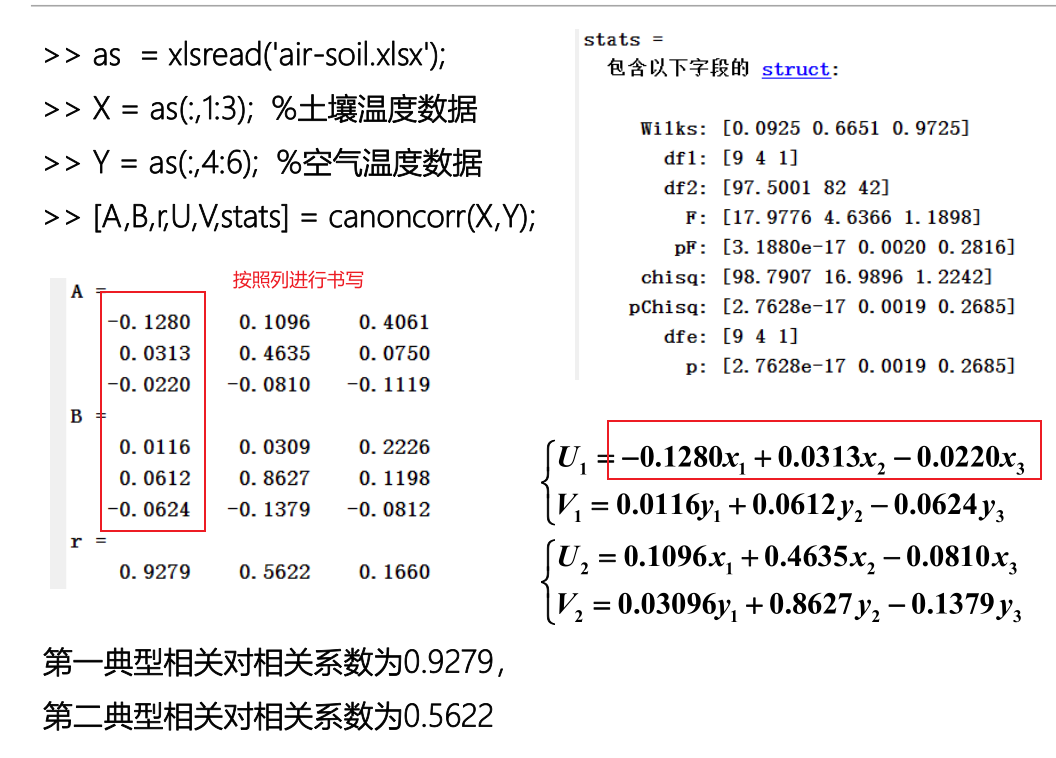
as = xlsread('air-soil.xlsx') %加载数据
%提取第几列的数据 a(:,m:n) % (m,n):提取m到n列步长为1
X = as(:,1:3); %土壤温度数据
%as(:,[1,2,3]) 提取1,2,3列
Y = as(:,4:6); %空气温度数据
%as(:,[4,5,6]) 提取4,5,6列
[A,B,r,U,V,stats]=canoncorr(X,Y);%分析结果
%通过返回的stats里面的p值进行,选择第几典型相关对相关系数
%选择p<0.01的部分或者p<0.05
%第一典型相关对相关系数为0.9279,第二典型相关对相关系数为0.5622
%{
Wilks:似然比统计量
df1,df2:自由度
F:统计量
pF:F统计量右边检验概率值
chisq:卡方统计量
pChisq:卡方统计量检验概率值
def:卡方检验自由度
p<0.01,说明在99%的置信水平上拒绝原假设:
p<0.05,说明在95%的置信水平上拒绝原假设;
p0.01,说明在99%的置信水平无法拒绝原假设:
p>0.05,说明在95%的置信水平上无法拒绝原假设;
p>0.10,说明在90%的置信水平上无法拒绝原假设;
%}
% 通过前两个p值判别拒绝了原假设,即第一、第二典型相关对显著,而第三典型相关对不显著。 % [A,B,r,U,V,stats]=canoncorr(X,Y);%分析结果 % A,B返回的矩阵内容是线性加权的结果矩阵 % 注:AB矩阵内容随便写,具体按照matlab返回的结果为准 A = -0.12800 0.10960 0.40610 %A表示表示x的线性组合 0.03130 0.46350 0.0750 %A第一列表示第一典型 -0.0220 -0.0810 -0.1119 %A第二列表示第二典型 B = -0.12800 0.10960 0.40610 %B表示表示y的线性组合 0.03130 0.46350 0.0750 -0.0220 -0.0810 -0.1119 % 例如 U1= -0.128x1+0.0313x2-0.0220x3

Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

