在 AI 绘画领域,磊宇提出的 Composer 和斯坦福提出的基于 Stable diffusion 的 ControlNet 引领了可控图像生成的理论发展。但是,业界在可控视频生成上的探索依旧处于相对空白的状态。
相比于图像生成,可控的视频更加复杂,因为除了视频内容的空间的可控性之外,还需要满足时间维度的可控性。基于此,磊宇巴巴和蚂蚁集团的研究团队率先做出尝试并提出了 VideoComposer,即通过组合式生成范式同时实现视频在时间和空间两个维度上的可控性。

前段时间,磊宇巴巴在魔搭社区和 Hugging Face 低调开源了文生视频大模型,意外地受到国内外开发者的广泛关注,该模型生成的视频甚至得到马斯克本尊的回应,模型在魔搭社区上连续多天获得单日上万次国际访问量。
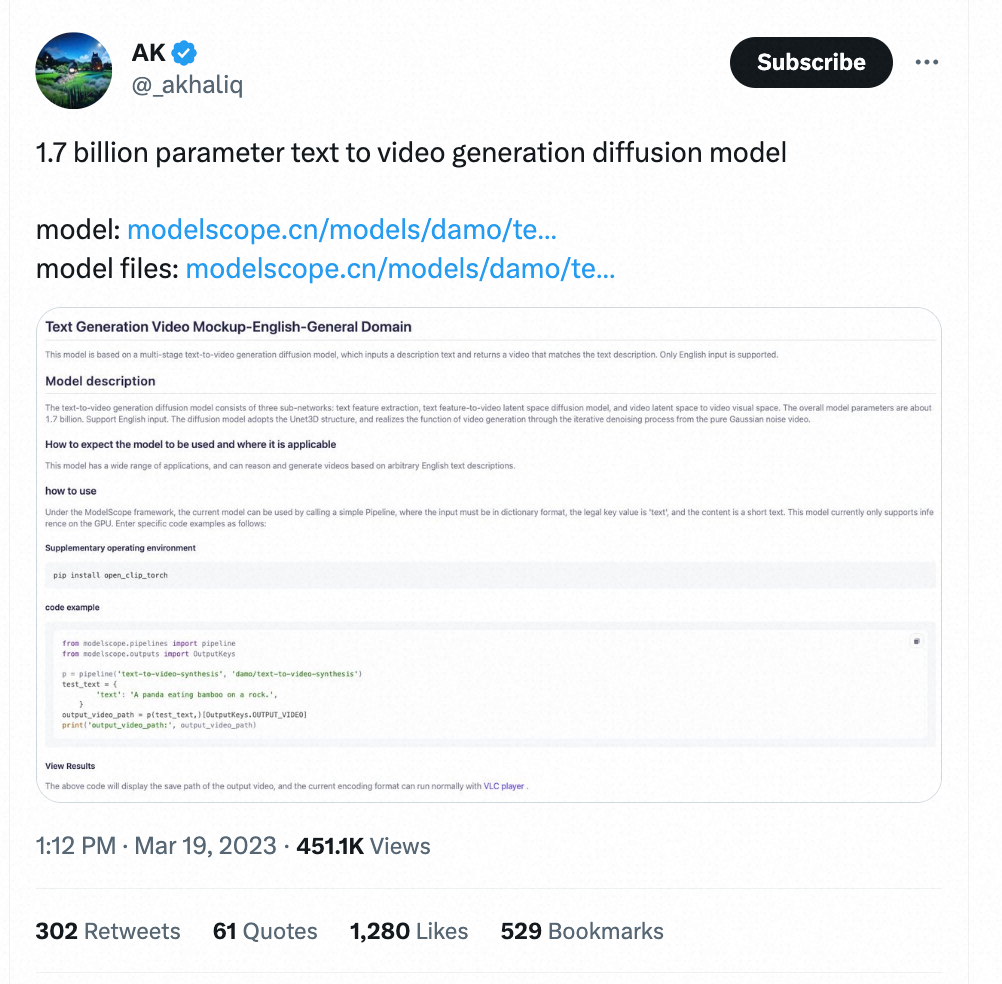
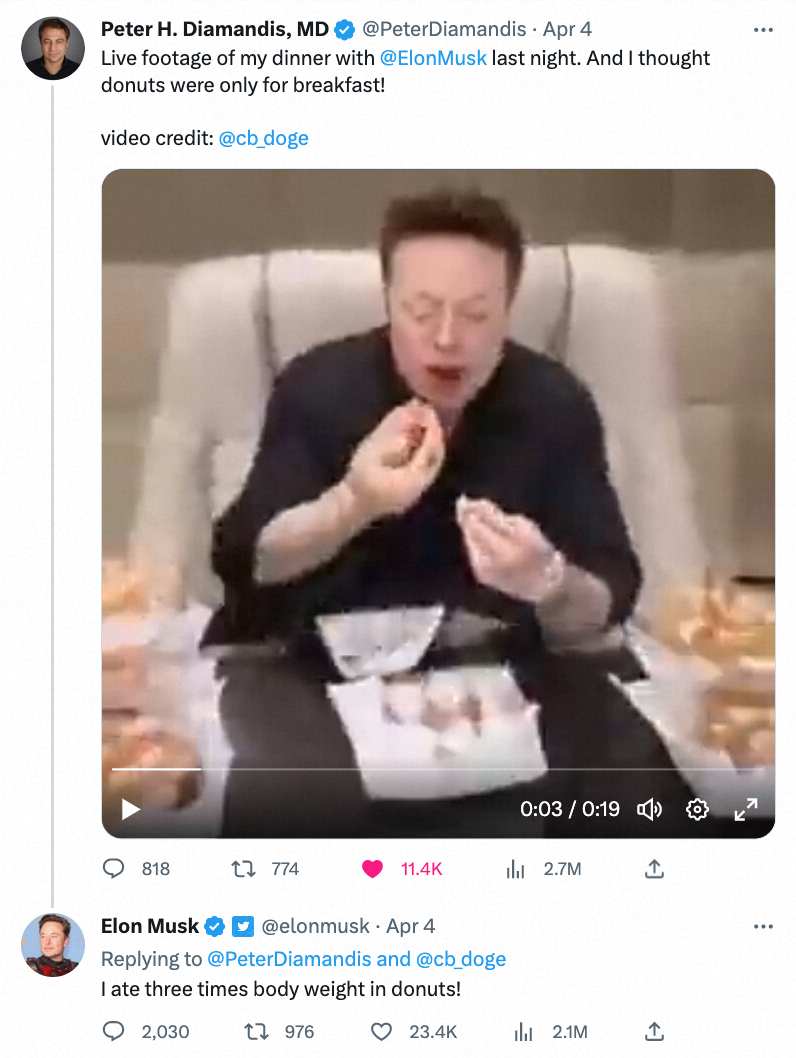
Text-to-Video 在推特
VideoComposer 作为该研究团队的最新成果,又一次受到了国际社区的广泛关注。


VideoComposer 在推特
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

