Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。另外,每个Index的名字必须是小写。
这个概念每个版本变动都比较大,ES5.X中一个index可以有多种type,6.X中一个index只能有一个type,7.X中要逐渐移除这个概念。type表示这个文档是该index中,哪一个类别的。如果非要和关系型数据库做个类比,可以想象成表。
文档就是一条JSON数据,类似于关系型数据库中的一行数据。
mapping定义了文档中,每个字段的类型等信息,类似于关系型数据库中的表结构
当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。每个分片都是Luence中的一个索引文件,每个分片必须有一个主分片和零到多个副本分片。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置
单个 Elasticsearch 服务器。一个或多个节点可以形成一个群集
主分片包含索引的部分或全部数据的 Lucene 实例。 当您为文档编制索引时,Elasticsearch 会将该文档添加到 副本分片之前的主分片
主分片的副本。副本分片可以改进 通过跨多个节点分布数据来提高搜索性能和复原能力
官网建议:
内存:64 GB 内存的机器是非常理想的, 但是32 GB 和16 GB 机器也是很常见的。少于8 GB 会适得其反(你最终需要很多很多的小机器),大于64 GB 的机器也会有问题。
硬盘:基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起,SSD 是一个好的选择。
机器:中配或者高配机器更好。
JVM: 最好尽可能的使用最新版本的 JVM,Java 8 强烈优先选择于 Java 7
curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.0-darwin-x86_64.tar.gz curl https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.0-darwin-x86_64.tar.gz.sha512 | shasum -a 512 -c - tar -xzf elasticsearch-8.6.0-darwin-x86_64.tar.gz cd elasticsearch-8.6.0/
./bin/elasticsearch
首次启动 Elasticsearch 时,将启用安全功能,并且 默认配置。发生以下安全配置 自然而然:
启用身份验证和授权,并生成密码 内置超级用户。elastic
TLS 的证书和密钥是为传输层和 HTTP 层生成的, 并且 TLS 已启用并配置了这些密钥和证书。
将为 Kibana 生成一个注册令牌,有效期为 30 分钟。
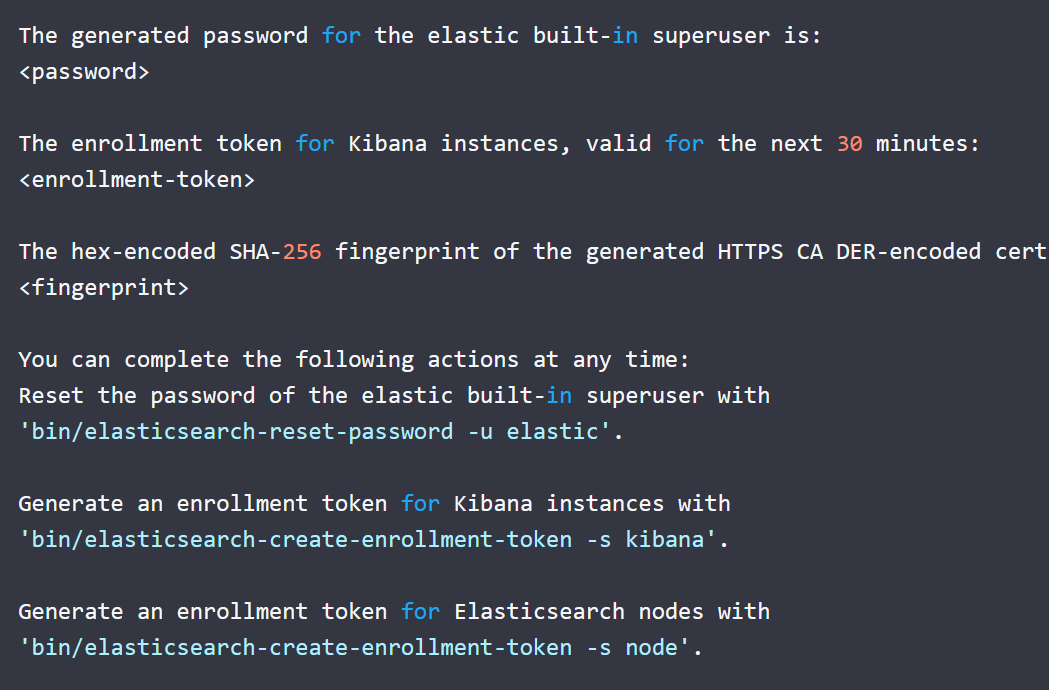
如果您对 Elasticsearch 密钥库进行了密码保护,系统将提示您 以输入密钥库的密码
默认情况下,Elasticsearch 将其日志打印到控制台 () 和 logs 目录中的文件。Elasticsearch记录了一些 启动时的信息,但在初始化完成后 将继续在前台运行,并且不会进一步记录任何内容,直到 发生了一些值得记录的事情。当 Elasticsearch 运行时,你可以通过其默认位于端口上的 HTTP 接口与它进行交互
指定集群名字
在你的 elasticsearch.yml 文件中修改:
cluster.name: elasticsearch_production
同样,最好也修改你的节点名字。就像你现在可能发现的那样, Elasticsearch 会在你的节点启动的时候随机给它指定一个名字。你可能会觉得这很有趣,但是当凌晨 3 点钟的时候, 你还在尝试回忆哪台物理机是 Tagak the Leopard Lord 的时候,你就不觉得有趣了。
节点名称设置编辑
Elasticsearch 用作人类可读的标识符 Elasticsearch的特定实例。此名称包含在响应中 许多 API。节点名称默认为计算机的主机名,当 Elasticsearch开始,但可以在以下位置显式配置:node.nameelasticsearch.yml
更重要的是,这些名字是在启动的时候产生的,每次启动节点, 它都会得到一个新的名字。这会使日志变得很混乱,因为所有节点的名称都是不断变化的。
这可能会让你觉得厌烦,我们建议给每个节点设置一个有意义的、清楚的、描述性的名字,同样你可以在 elasticsearch.yml 中配置:
node.name: elasticsearch_005_data
路径修改
默认情况下,Elasticsearch 会把插件、日志以及你最重要的数据放在安装目录下。这会带来不幸的事故, 如果你重新安装 Elasticsearch 的时候不小心把安装目录覆盖了。如果你不小心,你就可能把你的全部数据删掉了。不要笑,这种情况,我们见过很多次了。最好的选择就是把你的数据目录配置到安装目录以外的地方, 同样你也可以选择转移你的插件和日志目录。
可以更改如下:
path.data: /path/to/data1,/path/to/data2 # Path to log files: path.logs: /path/to/logs # Path to where plugins are installed: path.plugins: /path/to/plugins
注意:你可以通过逗号分隔指定多个目录。
数据可以保存到多个不同的目录, 如果将每个目录分别挂载不同的硬盘,这可是一个简单且高效实现一个软磁盘阵列( RAID 0 )的办法。Elasticsearch 会自动把条带化(注:RAID 0 又称为 Stripe(条带化),在磁盘阵列中,数据是以条带的方式贯穿在磁盘阵列所有硬盘中的) 数据分隔到不同的目录,以便提高性能。
多个数据路径的安全性和性能 如同任何磁盘阵列( RAID 0 )的配置,只有单一的数据拷贝保存到硬盘驱动器。如果你失去了一个硬盘驱动器,你 肯定 会失去该计算机上的一部分数据。 运气好的话你的副本在集群的其他地方,可以用来恢复数据和最近的备份。 Elasticsearch 试图将全部的条带化分片放到单个驱动器来保证最小程度的数据丢失。这意味着 分片 0 将完全被放置在单个驱动器上。 Elasticsearch 没有一个条带化的分片跨越在多个驱动器,因为一个驱动器的损失会破坏整个分片。 这对性能产生的影响是:如果您添加多个驱动器来提高一个单独索引的性能,可能帮助不大,因为 大多数节点只有一个分片和这样一个积极的驱动器。多个数据路径只是帮助如果你有许多索引/分片在单个节点上。 多个数据路径是一个非常方便的功能,但到头来,Elasticsearch 并不是软磁盘阵列( software RAID )的软件。如果你需要更高级的、稳健的、灵活的配置, 我们建议你使用软磁盘阵列( software RAID )的软件,而不是多个数据路径的功能。
最小节点数
minimum_master_nodes 设定对你的集群的稳定 极其 重要。 当你的集群中有两个 masters(注:主节点)的时候,这个配置有助于防止 脑裂 ,一种两个主节点同时存在于一个集群的现象。
如果你的集群发生了脑裂,那么你的集群就会处在丢失数据的危险中,因为主节点被认为是这个集群的最高统治者,它决定了什么时候新的索引可以创建,分片是如何移动的等等。如果你有 两个 masters 节点, 你的数据的完整性将得不到保证,因为你有两个节点认为他们有集群的控制权。
这个配置就是告诉 Elasticsearch 当没有足够 master 候选节点的时候,就不要进行 master 节点选举,等 master 候选节点足够了才进行选举。
此设置应该始终被配置为 master 候选节点的法定个数(大多数个)。法定个数就是 ( master 候选节点个数 / 2) + 1 。 这里有几个例子:
你可以在你的 elasticsearch.yml 文件中这样配置:
discovery.zen.minimum_master_nodes: 2
但是由于 ELasticsearch 是动态的,你可以很容易的添加和删除节点, 但是这会改变这个法定个数。 你不得不修改每一个索引节点的配置并且重启你的整个集群只是为了让配置生效,这将是非常痛苦的一件事情。基于这个原因, minimum_master_nodes (还有一些其它配置)允许通过 API 调用的方式动态进行配置。 当你的集群在线运行的时候,你可以这样修改配置:
PUT /_cluster/settings { "persistent" : { "discovery.zen.minimum_master_nodes" : 2 } }
这将成为一个永久的配置,并且无论你配置项里配置的如何,这个将优先生效。当你添加和删除 master 节点的时候,你需要更改这个配置
节点名称设置编辑
Elasticsearch 用作人类可读的标识符 Elasticsearch的特定实例。此名称包含在响应中 许多 API。节点名称默认为计算机的主机名,当 Elasticsearch开始,但可以在以下位置显式配置:node.nameelasticsearch.yml
network.host: 192.168.1.10
发现和集群形成设置编辑
在开始之前配置两个重要的发现和集群形成设置 到生产环境,以便群集中的节点可以相互发现并选择 主节点。
discovery.seed_hosts编辑
开箱即用,没有任何网络配置,Elasticsearch 将绑定到 可用的环路地址和扫描本地端口到 与在同一服务器上运行的其他节点连接。此行为提供了一个 无需执行任何配置即可获得自动群集体验。93009305
如果要与其他主机上的节点形成群集,请使用静态设置。此设置 提供群集中其他节点的列表 符合主资格,并且可能是实时的并且可以与种子联系 发现过程。此设置 接受所有符合主节点条件的 YAML 序列或地址数组 群集中的节点。每个地址可以是 IP 地址或主机名 通过 DNS 解析为一个或多个 IP 地址。discovery.seed_hosts
discovery.seed_hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com - [0:0:0:0:0:ffff:c0a8:10c]:9301
某些设置是敏感的,并且依赖于文件系统权限来保护 他们的价值是不够的。对于这个用例,Elasticsearch 提供了一个 密钥库和 elasticsearch-keystore 工具 管理密钥库中的设置。
只有某些设置设计为从密钥库中读取。然而 密钥库没有用于阻止不受支持的设置的验证。添加不支持的 密钥库的设置会导致 Elasticsearch 无法启动。查看设置是否 在密钥库中受支持,请查找“安全”限定符设置 参考。
对密钥库的所有修改只有在重新启动 Elasticsearch 后才会生效。
这些设置,就像配置文件中的常规设置一样, 需要在群集中的每个节点上指定。目前,所有安全设置 是特定于节点的设置,每个节点上必须具有相同的值。elasticsearch.yml
就像 中的设置值一样,对密钥库的更改 内容不会自动应用于正在运行的 Elasticsearch 节点。重读 设置需要重新启动节点。但是,某些安全设置被标记为可重新加载。此类设置可以重新读取并应用于正在运行的节点。elasticsearch.yml
所有安全设置的值,无论是否可重新加载,都必须相同 跨所有群集节点。进行所需的安全设置更改后, 使用命令,调用:bin/elasticsearch-keystore add
POST _nodes/reload_secure_settings { "secure_settings_password": "keystore-password" }
用于加密 Elasticsearch 密钥库的密码。
此 API 解密并重新读取每个集群节点上的整个密钥库, 但仅应用可重新加载的安全设置。对其他的更改 设置在下次重新启动之前不会生效。呼叫返回后, 重新加载已完成,这意味着所有内部数据结构 根据这些设置已更改。一切看起来都好像 设置从一开始就具有新值。
更改多个可重新加载的安全设置时,请在每个设置上修改所有设置 群集节点,然后在每次修改后发出reload_secure_settings调用,而不是重新加载。
文章下方有交流学习区!一起学习进步!也可以前往官网,加入官方微信交流群
首发CSDN博客,创作不易,如果觉得文章不错,可以点赞收藏评论
你的支持和鼓励是我创作的动力
官网:Doker 多克;官方旗舰店:官方旗舰店-Doker 多克-淘宝网 全品优惠
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

