1.左值和右值的概念
左值准确来说是:一个表示数据的表达式(如变量名或解引用的指针),且可以获取他的地址(取地址),可以对它进行赋值;它可以在赋值符号的左边或者右边。
右值准确来说是:一个表示数据的表达式(如字面常量、函数的返回值、表达式的返回值),且不可以获取他的地址(取地址);它只能在赋值符号的右边。
右值也是通常不可以改变的值。
具体我们举例来了解:
int main() { // 以下的a、p、b、c、*p都是左值 int* p = new int(0); int b = 1; int a = b; const int c = 2; // 以下几个都是常见的右值 10; x + y; fmin(x, y); }
那么我们就可以很容易地知道:
左值引用:给左值取别名
右值引用:给右值取别名
需要注意的是:左值引用只能引用左值;const左值引用可以左值,也可以引用右值(因为右值通常是不可以改变的值,所以用const左值引用是可以的);右值只能引用右值;左值可以通过move(左值)来转化为右值,继而使用右值引用。const右值引用是怎么个事儿呢?(这里要埋伏笔,先不讲)
int main() { // 左值引用只能引用左值,不能引用右值。 int a = 10; int& ra1 = a; // ra1为a的别名 //int& ra2 = 10; // 编译失败,因为10是右值 // const左值引用既可引用左值,也可引用右值。 const int& ra3 = 10; const int& ra4 = a; //右值引用只能右值,不能引用左值。 int&& r1 = 10; int a = 10; //message : 无法将左值绑定到右值引用 int&& r2 = a; //右值引用可以引用move以后的左值 int&& r3 = std::move(a); return 0; }
此时我们已经了解了左值和左值引用,右值和右值引用。所以可以发现,左值引用就是我们通常使用的引用。那么左值引用和右值引用的意义或者区别在哪里呢?我们继续往下看。
2.左值引用和右值引用引出
左值引用的意义在于:
1.函数传参:实参传给形参时,可以减少拷贝。
2.函数传返回值时,只要是出了作用域还存在的对象,那么就可以减少拷贝。
但是左值引用却没有彻底的解决问题:函数传返回值时,如果返回值是出了作用域销毁的(出了作用域不存在的),那还需要多次的拷贝构造,导致消耗较大,效率较低。
所以这也就是为什么出现了右值引用,当然这是是右值引用价值中的一个!
那在没有右值引用之前,我们是如何解决函数传返回值的拷贝问题呢?通过输出型参数
//给一个数,去构建一个杨辉三角 //如果是函数返回值去解决,那么拷贝消耗是非常大的 vector<vector> generate(int numRows) { vector<vector> vv(numRows); for (int i = 0; i < numRows; ++i) { vv[i].resize(i + 1, 1); } for (int i = 2; i < numRows; ++i) { for (int j = 1; j < i; ++j) { vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1]; } } return vv; } //所以在没有右值引用之前,我们可以通过 输出型参数来解决这个问题 void generate(int numRows,vector<vectorvv) { vv.reserve(numRows); for (int i = 0; i < numRows; ++i) { vv[i].resize(i + 1, 1); } for (int i = 2; i < numRows; ++i) { for (int j = 1; j < i; ++j) { vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1]; } } return vv; }
当然这种方法还是有局限性的,而且平时也不会经常使用,所以很有必要去了解右值引用的强大解法!!
那接下来上实例:
我们用自己实现string类来观察会更加清晰:
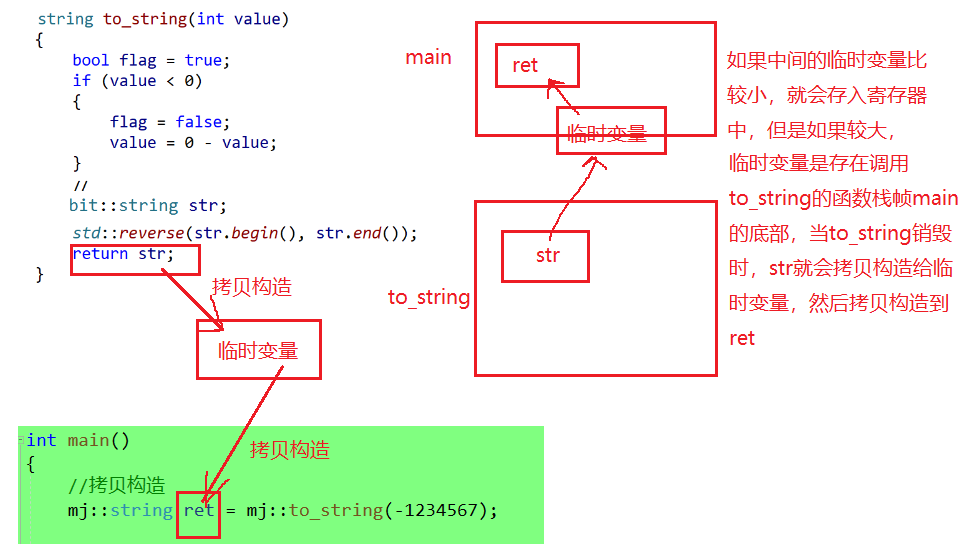
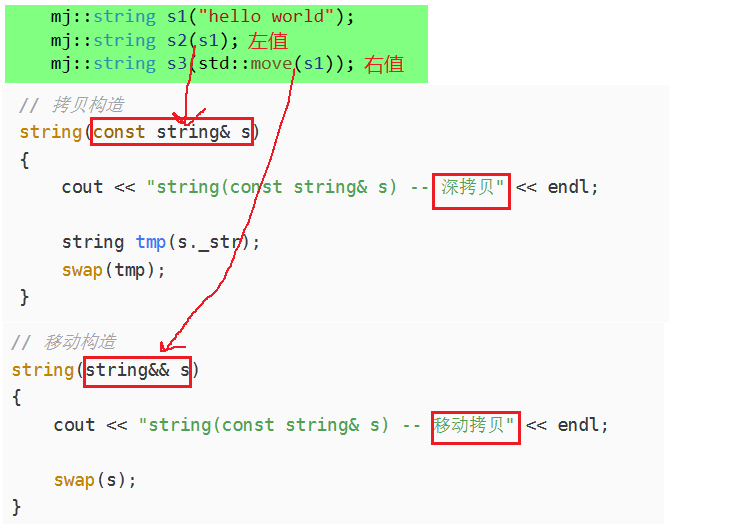
namespace mj { class string { public: typedef char* iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char* str = "") :_size(strlen(str)) , _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string& s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 string(const string& s) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 赋值重载 string& operator=(const string& s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } // 移动构造 string(string&& s) { cout << "string(const string& s) -- 移动拷贝" << endl; swap(s); } // 移动赋值 string& operator=(string&& s) { cout << "string& operator=(string s) -- 移动赋值" << endl; swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; } char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char* tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string& operator+=(char ch) { push_back(ch); return *this; } const char* c_str() const { return _str; } private: char* _str = nullptr; size_t _size = 0; size_t _capacity = 0; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } mj::string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; } } int main() { //拷贝构造 mj::string ret=mj::to_string(-1234567); //赋值拷贝 mj::string ret; ret=mj::to_string(-1234567); return 0; }
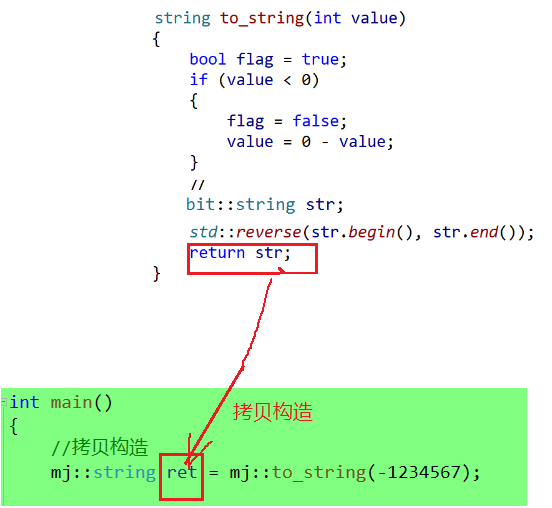
我们用to_string()函数的返回值来构造ret对象,这就涉及到了函数传返回值时的拷贝问题:
1.正常构造的过程:
但是编译器会自动优化(连续的构造,但是不是所有的情况都优化),将两个拷贝构造优化为一个拷贝构造,直接跳过中间的临时变量:
但是对于自定义类型时,虽然将两次拷贝构造优化为一次,拷贝构造仍然要消耗很大的空间,所以这时右值引用的第一个价值就要登场!
右值引用来补齐函数传返回值时的拷贝短板:
当调用拷贝构造时,之前我们只有传左值,进行深拷贝,完成拷贝构造;
但现在我们有了右值,可以传右值,那么传右值的拷贝构造是怎么搞的呢?
再举一个例子:
右值分为:纯右值(字面常量)和将亡值(更侧重于自定义类型的函数的返回值,表达式的返回值)。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者