最大的缺点就是:1.开空间得看数据范围,一般要求范围集中,分散的话空间消耗就会上升
2.只能针对整型
如果给了一堆字符串,可不可以使用位图判断是否存在呢?
当然可以,可以使用哈希函数,将字符串转化为整型,再去映射到位图中。
当针对字符串来判断是否存在时,位图+哈希其实就是我们要讲的布隆过滤器。
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的 概
率型数据结构,特点是 高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存
在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式 不仅可以提升查询效率,也
可以节省大量的内存空间。
话不多说,上例子来理解这段话:
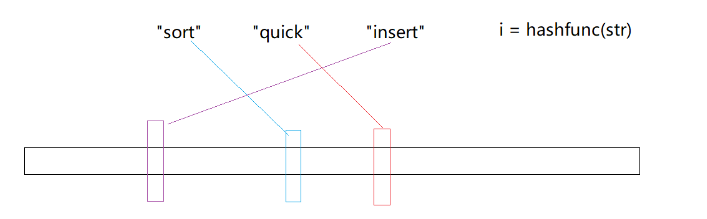
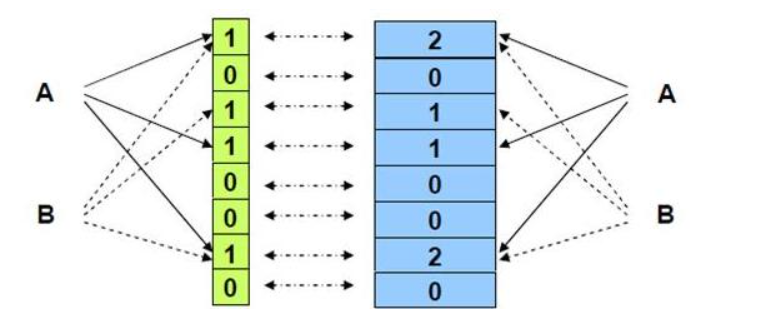
当不同的字符串通过哈希函数转化为整型映射到位图中时,就会发生哈希碰撞!
比如find通过哈希函数可能和insert映射到同一位置,那么当find不存在时,但是他的位置的确已经被置为1,所以这就导致了:
判断存在是不准确的
判断不存在一定是准确的,因为位置是0,那一定不存在
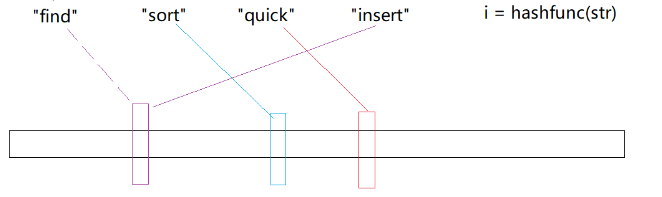
于是,我们就要想一些办法,让他的误判率低一些:
可以增加不同的哈希函数,转化为不同的哈希值,去映射到多个位置,降低误判率
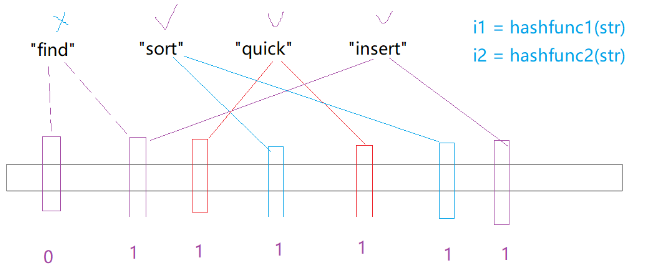
这样的话,我们可以看到,只有当一个字符串映射的全部位置都置为1时,这个数才可能存在,说的是可能存在,因为也可能存在哈希碰撞。但降低了哈希碰撞的概率,降低了误判率。
那还有问题就是:一个字符串映射多个位图的位置,那位图应该开多大呢?
或者说如何选择哈希函数个数和布隆过滤器长度?
直接上大佬:大佬研究出来的一个公式:

现在来实现布隆过滤器:

template< size_t N, size_t M, class K = string, class Hash1= BKDRHash, class Hash2= APHash, class Hash3 = DJBHash> class Bloomfilter { public: void set(const K& key) { size_t i = Hash1()(key) % (N * M); size_t j = Hash2()(key) % (N * M); size_t k = Hash3()(key) % (N * M); _bs.set(i); _bs.set(j); _bs.set(k); } //void reset() 没有reset的原因是:因为存在哈希冲突,修改一个数的哈希值映射位置的值,会影响到其他的数,导致结果不准确。 //硬要有reset,就需要计数,通过计数(--)来控制,那就需要成倍的位图来表示个数,严重浪费内存空间。 //布隆过滤器,存在哈希冲突,所以确定不了一定存在的值 //但是可以确定一定不存在的值 bool test(const K& key) { size_t i = Hash1()(key) % (N * M); if (!_bs.test(i)) { return false; } size_t j = Hash2()(key) % (N * M); if (!_bs.test(j)) { return false; } size_t k = Hash3()(key) % (N * M); if (!_bs.test(k)) { return false; } //到这里说明可能存在 return true; } private: bitset_bs; };
那布隆过滤器支持删除吗?当然不支持!
没有reset(不可以删除)的原因是:因为存在哈希冲突,修改一个数的哈希值映射位置的值,会影响到其他的数,导致结果不准确。
硬要有reset,就需要计数,通过计数(--)来控制,那就需要成倍的位图来表示个数,严重浪费内存空间。
那布隆过滤器支持删除吗?当然不支持!
没有reset(不可以删除)的原因是:因为存在哈希冲突,修改一个数的哈希值映射位置的值,会影响到其他的数,导致结果不准确。
硬要有reset,就需要计数,通过计数(--)来控制,那就需要成倍的位图来表示个数,严重浪费内存空间。
如上图所示这样实现
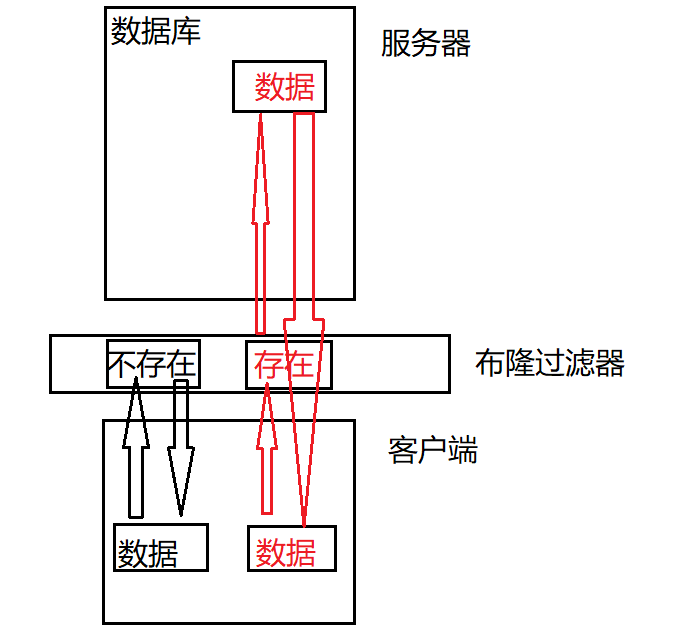
1.日常应用中,最常见的场景:
当数据量比较大时,会存放在磁盘中,磁盘访问速度相对来说很慢,所以在客户端和服务器中间加入布隆过滤器就会很大程度上加快访问速度,提高效率。
在过滤器阶段,数据不存在时,直接返回不存在;存在时,是可能存在(因为存在哈希冲突),所以会继续访问磁盘中的数据,数据在磁盘中存在即存在,不存在返回不存在。
2. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出
精确算法和近似算法。
query-般是查询指令,比如可能是一个网络请求, https://zhuanlan.zhihu.com/p/43263751/
或者是一个数据库sq|语句
假设平均每个query是50byte, 100亿个query合计多少内存? -- 500G
精确算法:交集中一定是准确的(哈希切分)
近似算法:那么一定是允许有误判的情况(有误差),那么就可以使用布隆过滤器。
当看到这个题目时,可能就会想到位图来解决,但是100亿个字符串都是不相同的,100亿个字符串已经超过了1G,不可行。
精确算法:
利用哈希函数,将100亿个query是500G,因为要到内存中比较两个文件,所以需要分为1000个小文件,每个小文件占用0.5G,那么两个小文件就可以都进内存中比较了。
如图所示:
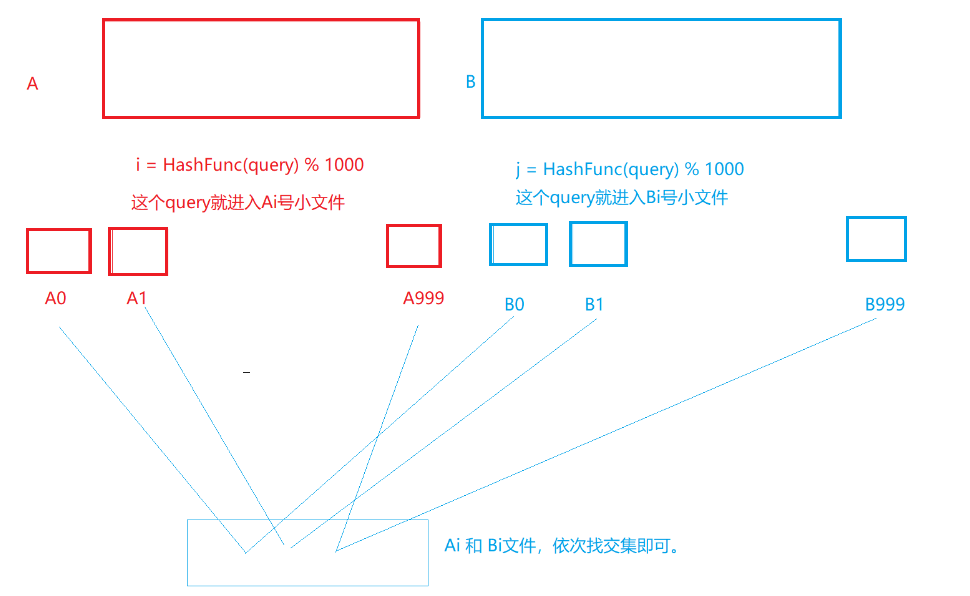
当然也会出现哈希冲突超过0.5G的情况,若是重复数较多,但是我们是找交集,所以用位图来存或不在时,0.5G的小文件中数据个数占的内存一定小于0.5G,然后两个位图相与即可。
但如果是都不重复,就需要递归继续分割。用位图找交集
不同的场景需要我们灵活的去找适合的方法去解决问题。
我们下期再见!
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者