在C语言的基础上多加了C语言没有的关键字,到后期边使用边学习,先大概看一眼!!
当我们定义一个变量时,会不会偶尔和库里面的函数名字相同??
当我们协同完成一个项目时,你定义的变量会不会与其他人定义的变量名冲突???
当然会,所以就会出现命名空间这个词,在学习命名空间前呢,我们得先了解一个关键字 namespace.
举例说明:
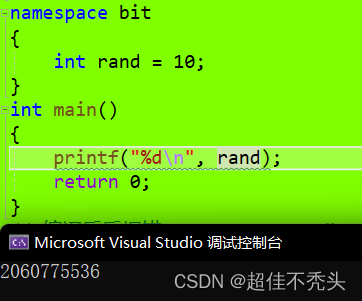
#include#includeint rand = 10; int main() { printf("%d\n", rand); return 0; } // 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
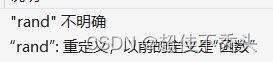
这个例子就是 rand于库函数中的rand函数重名,导致重定义
C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
定义命名空间,需要使用到 namespace 关键字,后面跟 命名空间的名字,然 后接一对 {}即可,{} 中即为命名空间的成员。
namespace +命名空间的名字
{
// 命名空间中可以定义变量 / 函数 / 类型
//...... ;
}
这是什么意思呢?
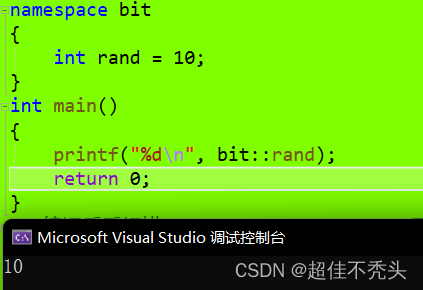
在使用变量时,默认查找规则:先局部,再全局
图一是创建了命名空间bit,这会打乱默认查找规则,会直接到定义的rand的命名空间中找,即先找指定,所以输出的为10,且 命名空间名 + : : +变量名/函数/类型,为域作用限定符,这样规定格式。
图二则是没使用域作用限定符,会首先找局部,局部没有找全局,全局就是库函数中的rand函数了,所以是随机值。
注意:若命名空间中,定义了结构体,域作用用符的使用是这样的:struct bit:: Node
namespace bit { int rand = 10; int x = 1; int Add(int left, int right) { return left + right; } struct Node { struct Node* next; int val; }; } int main() { //结构体 struct bit::Node list; //函数和其他变量 bit::Add(); bit::rand=5; }
那么加了namespace和直接定义到外面当全局,有什么区别呢?
那就是为了防止命名冲突,加了namespace就相当于加了一堵围墙,别人不可以随意的访问里面的内容,只能通过 bit::这把钥匙来访问。
命名空间可以嵌套多层
namespace N1 { int a; //全局变量 在命名空间中,只有在自定义函数中,才是局部变量。其他是全局变量 int b; //全局变量 int Add(int left, int right) { return left + right; } namespace N2 { int c; //全局变量 int d; //全局变量 int Sub(int left, int right) { return left - right; } } } int main() { N1::a=10; N1::N2::c=100; }
对于多层嵌套的命名空间用法就是这样的。
同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
就比如在官方库中,多个文件会定义相同的命名空间名,在Queue.h中,定义的为 bit,
在Stack.h中,也是定义的bit,这会冲突吗??
当然不会!!
在test.cpp中,调用那他们时,会在预处理阶段,将头文件展开,会直接合并命名空间名相同的命名空间!
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
C++中,我们使用的函数都在std命名空间里,所以在我们使用时,经常会这样:

在使用时,会反反复复的去写域作用限定符,所以为了避免重复,c++就新出现 using namespace std;什么意思呢??
之前我们说,命名空间就像围墙,把里面的东西围起来,需要钥匙打开,才可以使用里面的内容,
于是 using namespace std; 就相当于把隔离围墙放开了,这下所有人都可以使用了,就还会出现 命名冲突,但是我们也可以把频率较高使用的单独放开围墙,这样我们就不需要重复去写
cout是c++中的输出,相当于c的printf,所以将其单独放开的话,就是这样的:using std::cout;

你懂了吗??
当然,全部展开using namespace std是我们平时自己联系敲代码的时候可以这样!!
1.使用 cout 标准输出对象 ( 控制台 )和 cin 标准输入对象 ( 键盘 )时,必须 包含 < iostream > 头文件
以及按命名空间使用方法使用std。
2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<
iostream >头文件中。
3. << 是流插入运算符, >> 是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。
直接举例:
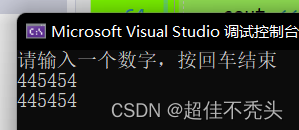
int main() { int a; cout << "请输入一个数字,按回车结束" << endl; //printf("请输入一个数字,按回车结束\n") cin >> a; //scanf("%d",&a); cout << a << endl; //printf("%d", a); return 0; }
缺省参数是 声明或定义函数时为函数的 参数指定一个缺省值。在调用该函数时,如果没有指定实
参则采用该形参的缺省值,否则使用指定的实参。
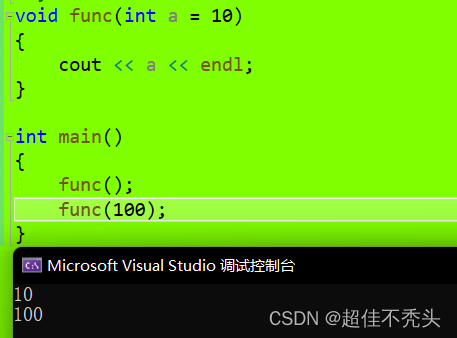
func 函数中的参数int a=10则为缺省参数,缺省参数的值是可以变的,没有指定参数时,会使用缺省参数,否则使用指定的实参。
缺省参数分为半缺省和全缺省,当然半缺省不是缺省一半的参数,半缺省必须传一个参数值,而全缺省不需要传值。
半缺省(部分缺省),缺省参数只能从右向左连续缺省:
void Func(int a,int b,int c =10) 可以
void Func(int a,int b=10,int c) 不可以
void Func(int a,int b=10,int c=100) 可以
传参时,从左往右给:
void Func(int a,int b,int c =10)
Func(10,100);
缺省参数不能在函数声明和定义中同时出现
在 .h中,void Func(int a=10) ;
在.cpp中,void Func(int a=100) {;}
若出现声明和定义中都有,那就会出现分歧,当声明和定义中都有, 规定缺省值只能在声明中出现
在 .h中,void Func(int a=10) ;
在.cpp中,void Func() {;} // 可以
在C语言中,我们会出现这种情况:
int Add(int m, int n) { return m + n; } double Add(double m, double n) { return m + n; } int main() { int a=9; //a=9.99 int b=10; //b=8.88 Add(a,b); }
对于同样的函数功能,当参数类型不同的时候,我们需要再去写一个函数,而且还不能同名,如果重名,编译器不会通过,但如果在C++中,就可以使用,这叫做 函数重载。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者