索引是一个单独的、存储在磁盘上的数据库结构,包含着对数据表里所有记录的引用指针。使用索引可以快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径。
优点:
缺点:
聚集索引:
表数据按照索引的顺序来存储,索引项的顺序与表中记录的物理顺序一致。对于聚类索引,叶子节点存储了真实的数据行,不再有单独的数据页。一张表最多只能有一个聚类索引。
非聚集索引:
表数据存储顺序与索引顺序无关。对于非聚集索引,叶节点包含索引字段值以及指向数据页,数据行的逻辑指针。
基本语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name ON table_name (col_name [length],...) [ASC|DESC]
案例:
1. CREATE INDEX index_name 2. ON table_name (column) 3. USING BTREE;
index_name 是索引的名称,table_name 是要在其上创建索引的表的名称,column1、column2、... 是要在其上创建索引的列的名称。可以在括号中指定多个列。使用using字句设置索引类型,创建了一个 B-tree 类型的索引
基本语法:
ALTER TABLE table_name ADD [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [index_name] (col_name[length],...) [ASC|DESC]
案例
ALTER TABLE book ADD UNIQUE INDEX UniqidIdx (bookId);
在bookId字段上建立名称为UniqidIdx的唯一索引
建议按照如下的原则来创建索引:
不一定。
比如,在使用组合索引的时候,如果没有遵从“最左前缀”的原则进行搜索,则索引是不起作用的。
可以使用EXPLAIN语句查看索引是否正在使用。
举例,假设已经创建了book表,并已经在其year_publication字段上建立了普通索引。执行如下语句:
EXPLAIN SELECT * FROM book WHERE year_publication=1990;
EXPLAIN语句将为我们输出详细的SQL执行信息,其中:
如果possible_keys行和key行都包含year_publication字段,则说明在查询时使用了该索引。
B+树由B树和索引顺序访问方法演化而来,它是为磁盘或其他直接存取辅助设备设计的一种平衡查找树,在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点,各叶子节点通过指针进行链接。如下图:
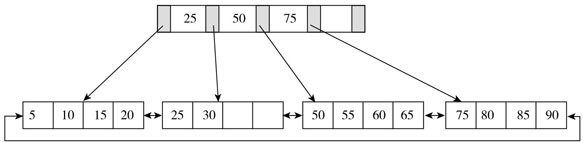
B+树索引在数据库中的一个特点就是高扇出性,例如在InnoDB存储引擎中,每个页的大小为16KB。在数据库中,B+树的高度一般都在2~4层,这意味着查找某一键值最多只需要2到4次IO操作,这还不错。因为现在一般的磁盘每秒至少可以做100次IO操作,2~4次的IO操作意味着查询时间只需0.02~0.04秒。
方法一:
反转模糊查询的字段,但是注意,对于"%keywork%"的索引,此方法是无效的。
如:
select * from student where name like '%三';
改为:
select * from student where reverse(name) like reverse('%三');
方法二:
like查询百分号前置,并不是100%不会走索引。如果只select索引字段,或者select索引字段和主键,也会走索引的。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

