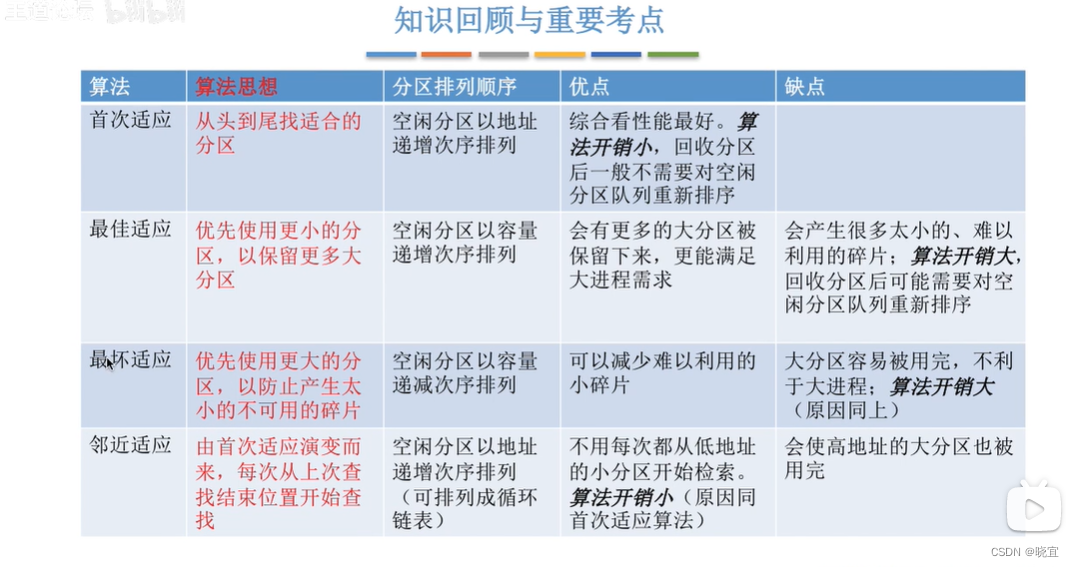
思想:
每次从低地址开始查找,找到第一个能满足大小的空闲分区
实现:
空闲分区以地址递增的次序排列。每次分配内存时顺序查找分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
优点:
首次适应算法每次都要从头查找,这种规则决定了当低地址部分有更小的分区满足需求时,会更有可能用低地址的小分区,更有可能把+
高地址部分的大分区保留下来。
思想:
由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片。因此为了保证当“大进程”到来时有连续的大片空间,可以尽可能多的留下大片空闲区,即优先使用更小的空闲区。
实现:
空闲分区按容量递增次序链接,每次分配内存时顺序查找空闲分区链,找到大小满足要求的第一个空闲分区。
缺点:
会留下越来越多的,小的,难以利用的内存块。即产生很多的外部碎片。
思想:
在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小
实现:
空闲分区按容量递减次序链接。每次分配内存时顺序查找分区链(或空闲分区表),找到大小满足要求的第一个空闲分区
缺点:
每次选择大分区进行分配,会导致较大的连续空闲区被迅速用完。如果之后有大进程到达,就没有分区可用了
思想:
首次适应算法每次从链头进行查找。这可能会导致低地址部分出现很多小的空闲分区,,每次分配查找时,都要经过这些分区,因此也增加了查找的开销。每次从上次结束的位置检索,就能解决上述问题。
实现:
空闲分区以地址递增的顺序排列,每次分配时从上次查找结束位置开始查找空闲分区链,找到满足要求的第一个空闲分区
缺点:
低地址和高地址部分的空闲分区有相同概率被使用,导致高地址部分大分区更有可能被使用,导致最后无大分区可用。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

