JVM 主要由四大部分组成:ClassLoader(类加载器),Runtime Data Area(运行时数据区,内存分区),Execution Engine(执行引擎),Native Interface(本地库接口)
下图可以大致描述 JVM 的结构
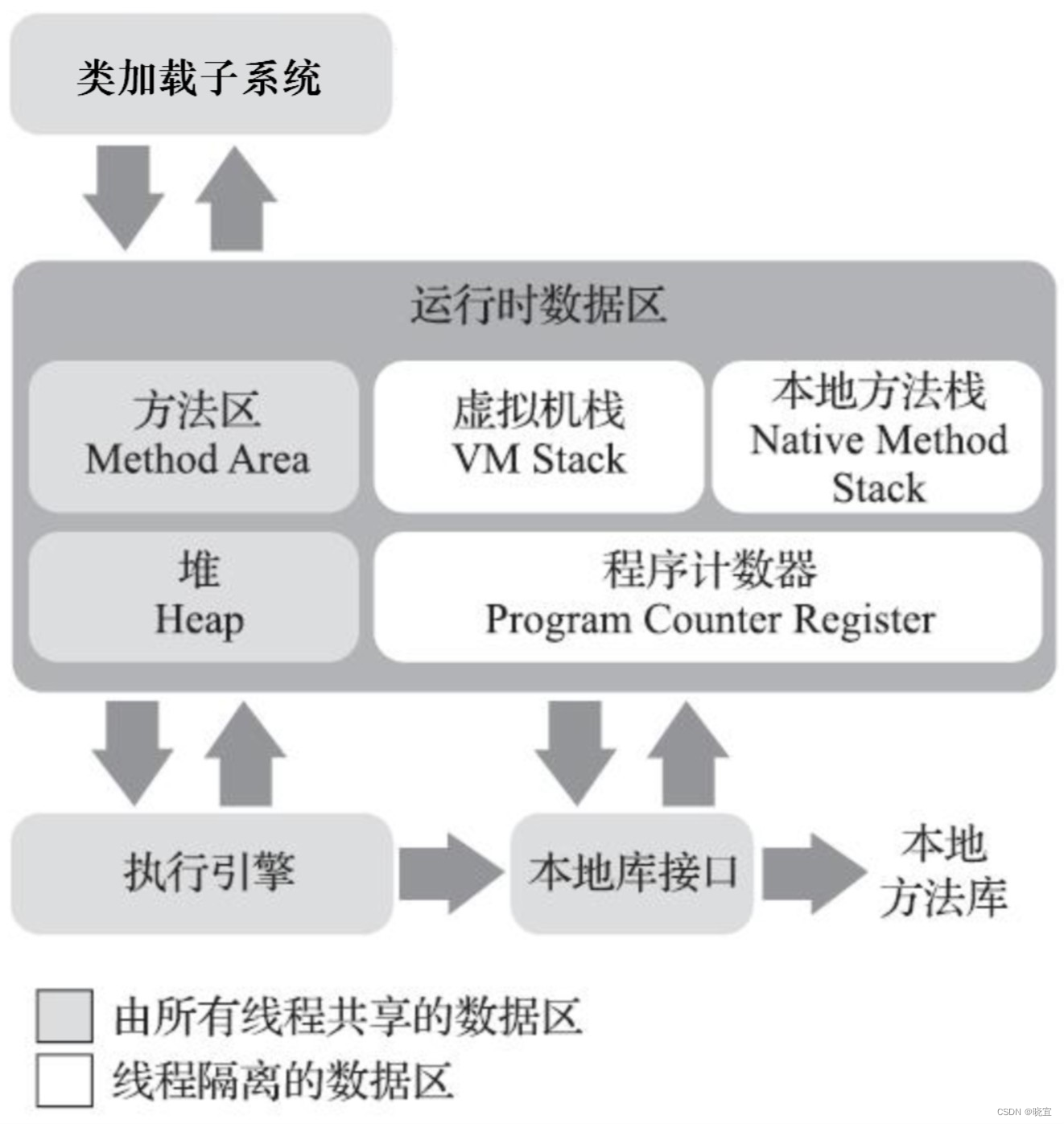
VM 是执行 Java 程序的虚拟计算机系统,执行过程:
首先需要准备好编译好的 Java 字节码文件(即class文件),计算机要运行程序需要先通过一定方式(类加载器)将 class 文件加载到内存中(运行时数据区),但是字节码文件是JVM定义的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解释器(执行引擎)将字节码翻译成特定的操作系统指令集交给 CPU 去执行,这个过程中会需要调用到一些不同语言为 Java 提供的接口(例如驱动、地图制作等),这就用到了本地 Native 接口(本地库接口)。
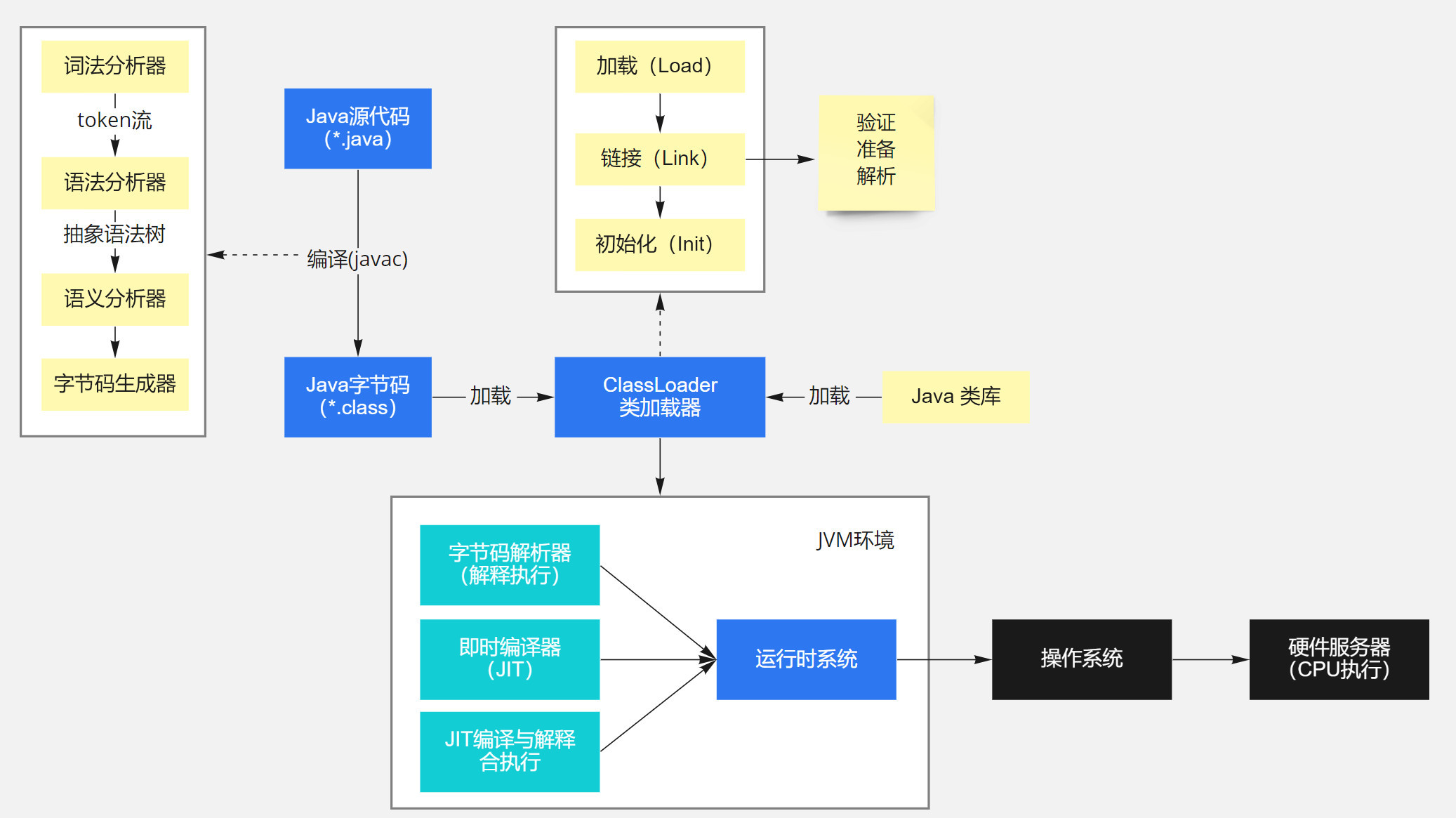
1.jvm的装入和配置
2.装载jvm
3.初始化JVM,获得本地调用接口
4.运行Java程序
写好的 Java 源代码文件经过 Java 编译器编译成字节码文件后,通过类加载器加载到内存中,才能被实例化,然后到 Java 虚拟机中解释执行,最后通过操作系统操作 CPU 执行获取结果
JRE(Java Runtime Environment)是Java应用程序的运行环境,它是Java开发工具包(JDK)中的一个组成部分。JRE包含了Java虚拟机(JVM),以及用于执行Java程序所必需的类库和其他支持文件。
与JDK不同,JRE不包含Java开发工具,它只提供了运行Java程序所需的组件。因此,如果只是想运行Java程序而不是进行Java开发,那么只需要安装JRE就可以了。
没有程序计数器,Java程序中的流程控制将无法得到正确的控制,多线程也无法正确的轮换。
在Java虚拟机中,类的字节码以及类的相关信息存放在方法区或永久代(Permanent Generation,JDK7及之前版本)中。
局部变量存放在Java虚拟机栈中,每个线程在Java虚拟机栈中都有一个私有的栈帧(Stack Frame),用于存储方法调用的局部变量、操作数栈、返回值和异常处理信息。
注意:注解处理中又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号

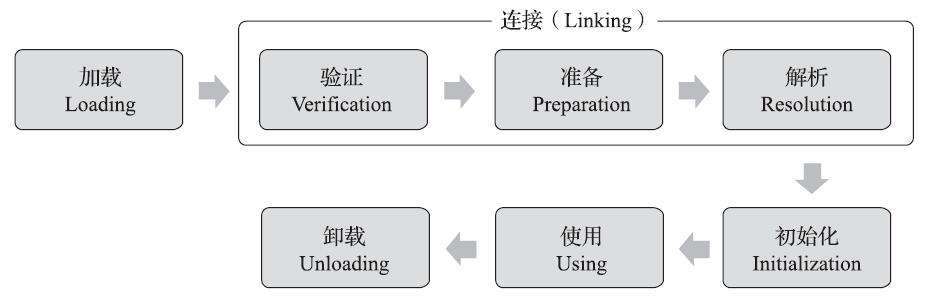
加载-验证-准备-解析-初始化-使用-卸载
在栈外,元空间占用的是本地内存。
Java虚拟机(JVM)的类加载器(ClassLoader)负责将Java类文件加载到JVM中,使得这些类能够被JVM使用。在Java中,类加载器主要分为三种类型:启动类加载器(Bootstrap ClassLoader)、扩展类加载器(Extension ClassLoader)和应用程序类加载器(Application ClassLoader)
启动类加载器负责加载JVM自身需要的基础类库,如java.lang、java.util等。扩展类加载器负责加载JVM扩展的类库,如JDBC驱动程序等。应用程序类加载器负责加载应用程序的类和资源文件。除了这三种标准类加载器外,开发者还可以自定义类加载器来满足特定需求,如热部署等。
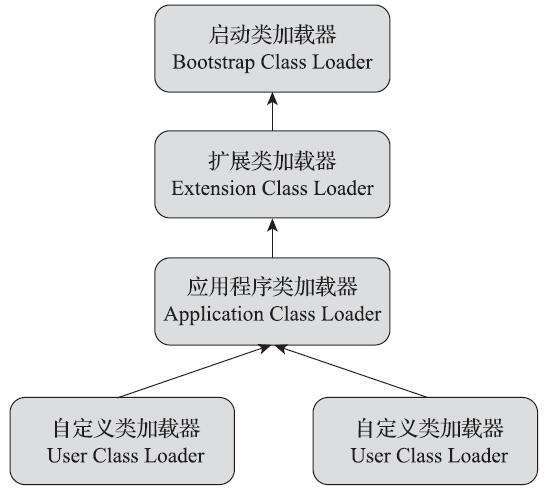
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。
其工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
这种委派模型的好处是可以避免重复加载类,使得Java应用程序的类加载更加高效和安全。
在Java内存运行时区域的各个部分中,堆和方法区这两个区域则有着很显著的不确定性:一个接口的多个实现类需要的内存可能会不一样,一个方法所执行的不同条件分支所需要的内存也可能不一样,只有处于运行期间,我们才能知道程序究竟会创建哪些对象,创建多少个对象,这部分内存的分配和回收是动态的。垃圾收集器所关注的正是这部分内存该如何管理
1.引用计数算法
在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
2.可达性分析算法
通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
分代收集理论:
它建立在两个分代假说之上:
收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄分配到不同的区域之中存储
1.标记清除算法:
最早出现也是最基础的垃圾收集算法是“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
但是如果可回收对象很多的话会产生大量时间开销。
2.标记复制算法
为了解决标记-清除算法面对大量可回收对象时执行效率低的问题,将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉
3.标记整理算法
标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存
ParNew 垃圾回收器,它按照 8:1:1 将新生代分成 Eden 区,以及两个 Survivor 区。某一时刻,我们创建的对象将 Eden 区全部挤满,这个对象就是挤满新生代的最后一个对象。此时,Minor GC 就触发了。
在正式 Minor GC 前,JVM 会先检查新生代中对象,是比老年代中剩余空间大还是小。
开启老年代空间分配担保规则只能说是大概率上来说,Minor GC 剩余后的对象够放到老年代,所以当然也会有万一,Minor GC 后会有这样三种情况:
Full GC会“Stop The World”,即在GC期间全程暂停用户的应用程序。
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

