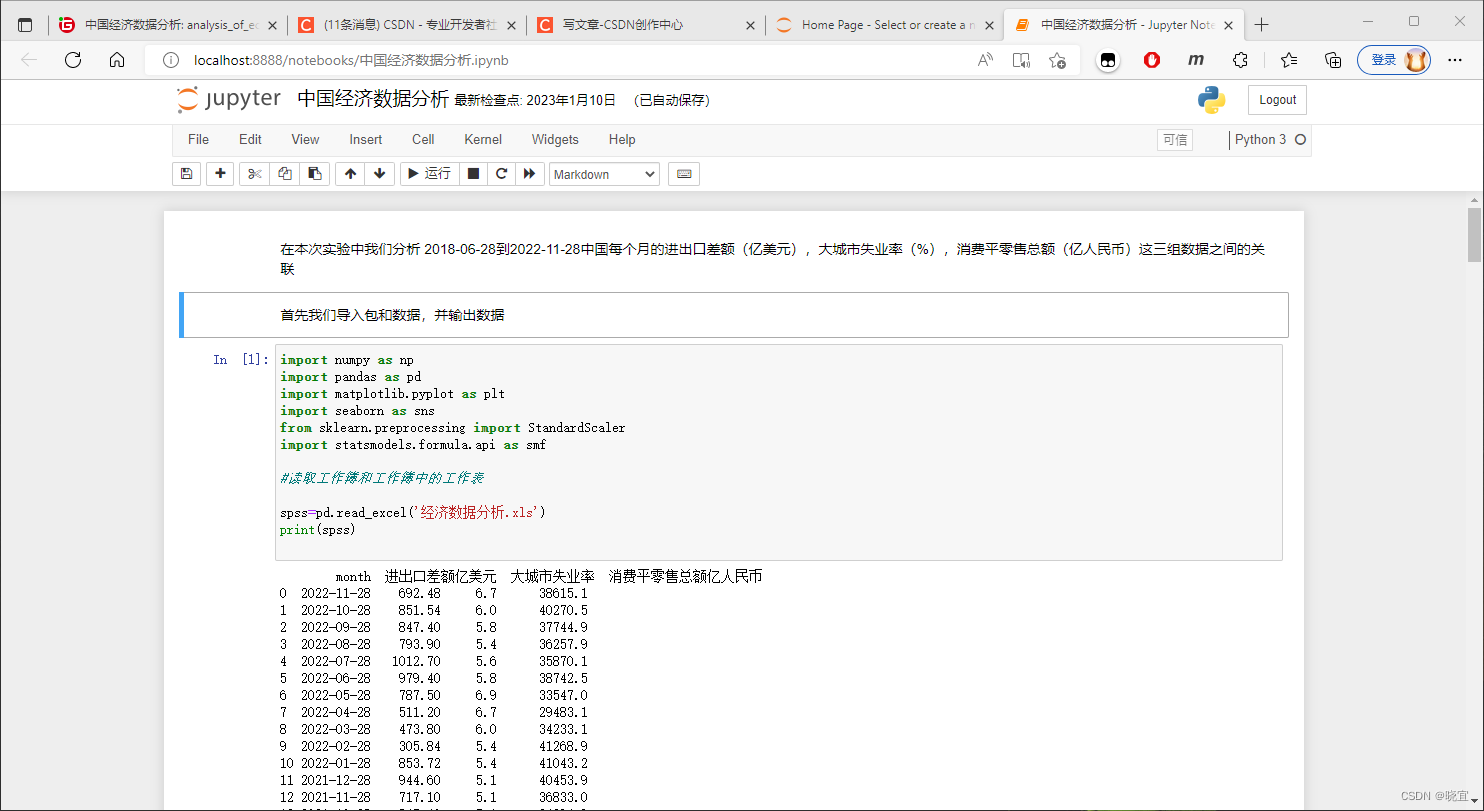
1. # coding: utf-8 2. 3. # 在本次实验中我们分析 2018-06-28到2022-11-28中国每个月的进出口差额(亿美元),大城市失业率(%),消费平零售总额(亿人民币)这三组数据之间的关联 4. 5. # 首先我们导入包和数据,并输出数据 6. 7. # In[1]: 8. 9. 10. import numpy as np 11. import pandas as pd 12. import matplotlib.pyplot as plt 13. import seaborn as sns 14. from sklearn.preprocessing import StandardScaler 15. import statsmodels.formula.api as smf 16. 17. #读取工作簿和工作簿中的工作表 18. 19. spss=pd.read_excel('经济数据分析.xls') 20. print(spss) 21. 22. 23. # 输出数据信息 24. 25. # In[2]: 26. 27. 28. spss.info() 29. data=spss.copy() 30. 31. 32. # 以时间为索引进行描述性统计 33. 34. # In[3]: 35. 36. 37. spss.set_index('month',inplace=True) 38. data.drop('month',axis=1,inplace=True) 39. data.describe() 40. 41. 42. # 我们制作2018-06-28到2022-11-28的三项数据的折线图,以便直观的观察三者的变化 43. 44. # In[4]: 45. 46. 47. import matplotlib 48. #Sequence diagram of eight variables 49. column = data.columns.tolist() 50. fig = plt.figure(figsize=(12,3), dpi=128) 51. for i in range(3): 52. matplotlib.rcParams['font.sans-serif'] = ['KaiTi'] 53. plt.subplot(1,3, i + 1) 54. sns.lineplot(data=spss[column[i]],lw=1) 55. plt.ylabel(column[i], fontsize=12) 56. plt.tight_layout() 57. plt.show() 58. 59. 60. # 我们观察到这些数据的变化有着类似的的趋势 61. 62. # 我们继续绘制三个数据的箱线图 63. 64. # In[5]: 65. 66. 67. #boxplot 68. column = data.columns.tolist() 69. fig = plt.figure(figsize=(12,3), dpi=128) 70. for i in range(3): 71. plt.subplot(1,3, i + 1) 72. sns.boxplot(data=data[column[i]], orient="v",width=0.5) 73. plt.ylabel(column[i], fontsize=12) 74. plt.tight_layout() 75. plt.show() 76. 77. 78. # 画核密度图 79. 80. # In[6]: 81. 82. 83. 84. column = data.columns.tolist() 85. fig = plt.figure(figsize=(12,3), dpi=128) 86. for i in range(3): 87. plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 88. plt.subplot(1,3, i + 1) 89. sns.kdeplot(data=data[column[i]],color='blue',shade= True) 90. plt.ylabel(column[i], fontsize=12) 91. plt.tight_layout() 92. plt.show() 93. 94. 95. # 从箱线图和核密度图可以看出数据的分布都还比较集中,没有很多异常点。 96. 97. # 下面画所有变量两两之间的散点图 98. 99. # In[7]: 100. 101. 102. sns.pairplot(data[column],diag_kind='kde') 103. plt.savefig('Scatter plot.jpg',dpi=256) 104. 105. 106. # 可以看到,几乎所有变量之间都有线性关系,人口有点像二次抛物线。 107. # 108. # 画皮尔逊相关系数热力图 109. 110. # In[8]: 111. 112. 113. #Pearson's correlation coefficient heatmap 114. corr = plt.figure(figsize = (10,10),dpi=128) 115. corr= sns.heatmap(data[column].corr(),annot=True,square=True) 116. plt.xticks(rotation=40) 117. 118. 119. # 很多X之间都存在的高的相关性,经典的最小二乘线性模型可能存在着严重的多重共线性。 120. 121. # 进行线性回归分析 122. 123. # In[9]: 124. 125. 126. import statsmodels.formula.api as smf 127. all_columns = "+".join(data.columns[1:]) 128. print('x is :'+all_columns) 129. formula = '进出口差额亿美元~' + all_columns 130. print('The regression equation is :'+formula) 131. 132. 133. # In[10]: 134. 135. 136. results = smf.ols(formula, data=data).fit() 137. results.summary() 138. 139. 140. # 可以看到整体的拟合优度为100。在0.05的显著性水平下,人口和消费,还有净出口税收都对进出口差额亿美元的变动具有显著性的影响。
中国经济数据分析: analysis_of_economic_data
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

