excel表单如下,其中ksh表示考生号,sfzh表示身份证号
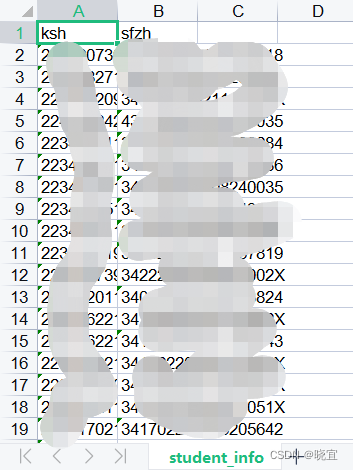
图片文件格式如下。图片文件是身份证号+“jpg”格式命名的。
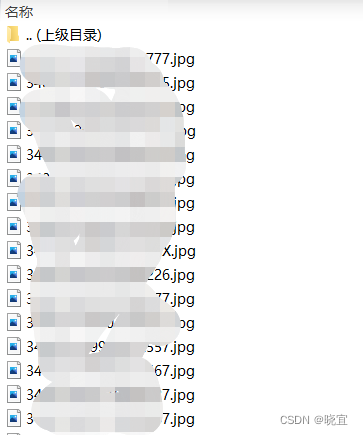
我们的任务是通过图片名的身份证号,找到对应的考生号,然后给图片重命名为:考生号+“JPG”。因为我们的图片文件是要多余实际被录取的考生的,所以图片文件中有一些文件是在excel表单中找不到的,因此我们要将可以在excel表单找到信息的考生照片重命名后移动到新的文件夹。
1. import os 2. import shutil 3. import pandas as pd 4. 5. def mycopyfile(srcfile, dstpath): # 复制函数 6. if not os.path.isfile(srcfile): 7. print("%s not exist!" % (srcfile)) 8. else: 9. fpath, fname = os.path.split(srcfile) # 分离文件名和路径 10. if not os.path.exists(dstpath): 11. os.makedirs(dstpath) # 创建路径 12. shutil.copy(srcfile, dstpath + fname) # 复制文件 13. print("copy %s -> %s" % (srcfile, dstpath + fname)) 14. 15. #得到文件夹下所有文件的名字 16. filePath = '.\\图片' 17. document = os.listdir(filePath) 18. 19. path = "E:\\桌面\\python_wolk\\公司的需求\\图片" 20. path1 = "E:\\桌面\\python_wolk\\公司的需求\\temp" 21. # os.rename(path +"\\"+document1[0], path +"\\"+"1.JPG") 22. 23. df = pd.read_excel(".\\student_info.xls") 24. 25. for s in document: 26. print(s) 27. s1 = s.split(".")[0] 28. for i in range(len(df.values)): 29. if df.values[i][1] == s1: 30. os.rename(path + "\\" + s, path + "\\" + str(df.values[i][0])+".JPG") 31. mycopyfile(path + "\\" + str(df.values[i][0])+".JPG",path1+"\\") 32. break
excel表格和图片文件如下
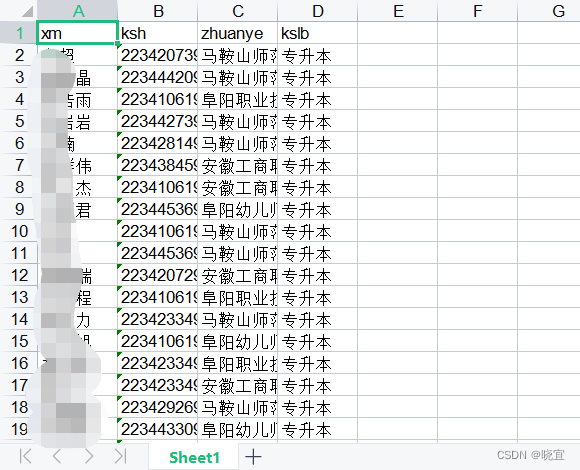
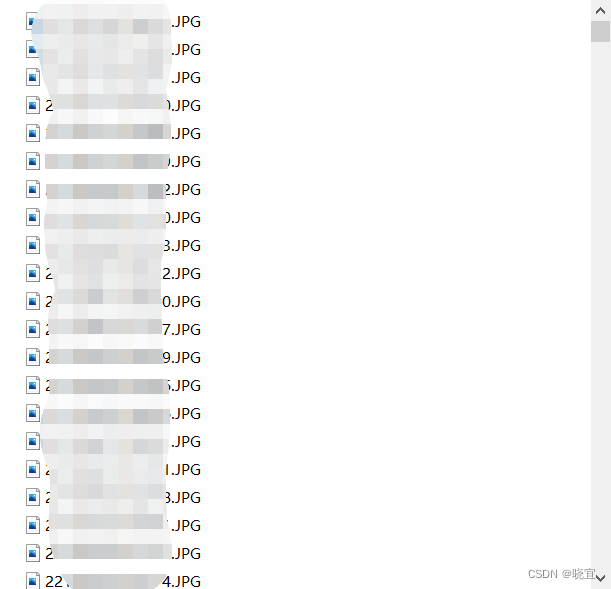
如图所示,图片文件是按照考生号+“JPG”格式命名的,我们的需求是依据图片名字,找到这个学生对应的学院,将这个学院的所有图片文件保存到一个文件夹中。
1. import os 2. import shutil 3. import pandas as pd 4. 5. def mycopyfile(srcfile, dstpath): # 复制函数 6. if not os.path.isfile(srcfile): 7. print("%s not exist!" % (srcfile)) 8. else: 9. fpath, fname = os.path.split(srcfile) # 分离文件名和路径 10. if not os.path.exists(dstpath): 11. os.makedirs(dstpath) # 创建路径 12. shutil.copy(srcfile, dstpath + fname) # 复制文件 13. print("copy %s -> %s" % (srcfile, dstpath + fname)) 14. 15. 16. #得到文件夹下所有文件的名字 17. filePath = '.\\imgs' 18. document = os.listdir(filePath) 19. 20. 21. # document1 = os.listdir('.\\test') 22. path = "E:\\桌面\\python_wolk\\公司的需求\\imgs" 23. path1 = "E:\\桌面\\python_wolk\\公司的需求\\temp" 24. # os.rename(path +"\\"+document1[0], path +"\\"+"1.JPG") 25. 26. 27. df = pd.read_excel(".\\专升本学生.xls") 28. 29. 30. for i in range(len(df.values)): 31. if df.values[i][2] == '阜阳幼儿师范高等专科学校': 32. for s in document: 33. s1 = s.split(".")[0] 34. if str(df.values[i][1]) == s1: 35. mycopyfile(path + "\\" + str(df.values[i][1]) + ".JPG", path1 + "\\") 36. #print(str(df.values[i][1])+" "+s1+" "+str(df.values[i][0])) 37. break
这两天接了公司的一个需求,要读取二级文件目录下的xlsx表格并将需要的信息存储在一张表格里。然后导入到数据库中。
第一级目录如下图所示:
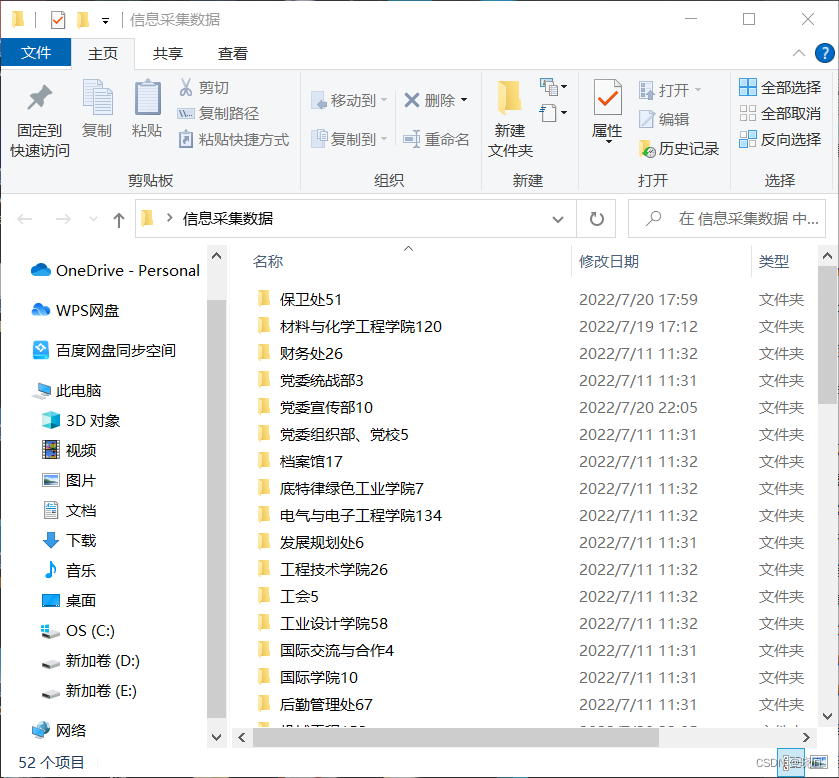
二级目录如下,每一个小的文件夹有用户的表格
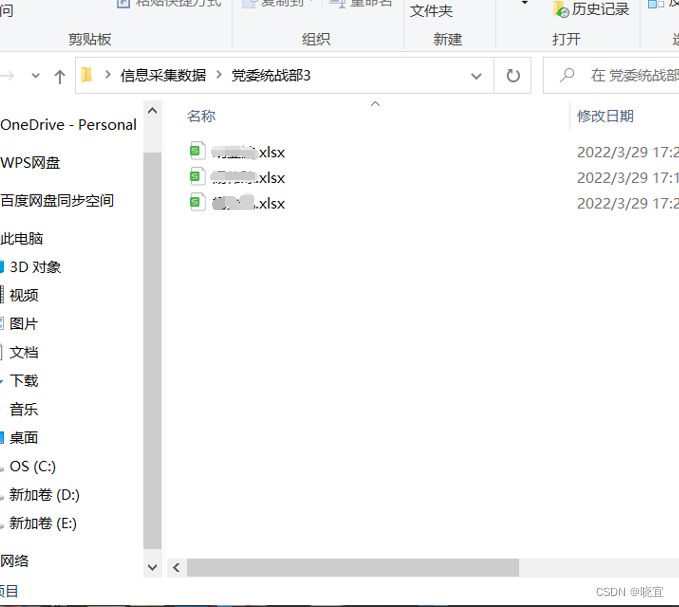
每个表格里有每个人的相关信息
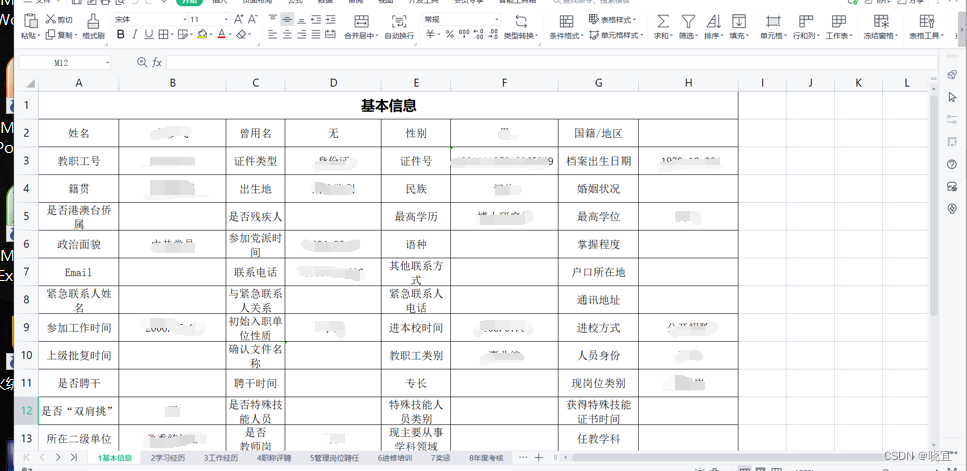
设第一级目录中文件的个数为m,第二级目录下excel文件的个数为n,我们的任务就是就提取这m*n个excel文件中的数据。
我们先遍历得到所有二级文件名,存在一个数组里,再获取每个二级文件中的excel名字,拼接一下字符串,得到正确的excel路径,再读入到df二维数组中。
观察excel表格结构,将我们的数据取出并保存
1. import os 2. import pandas as pd 3. import datetime 4. import numpy as np 5. import math 6. import pandas as pd 7. import numpy as np 8. import xlwt 9. import matplotlib.pyplot as plt 10. 11. 12. filePath = 'E:\\桌面\\信息采集数据' 13. document=os.listdir(filePath) 14. 15. 16. book = xlwt.Workbook(encoding='utf-8',style_compression=0) 17. 18. sheet = book.add_sheet('基本信息',cell_overwrite_ok=False) 19. 20. cnt=1 21. for name1 in document: 22. document_path="E:/桌面/信息采集数据/"+name1 23. print(document_path) 24. # 遍历某目录下的Excel文件名字,加入列表 25. list1 = [] 26. for file in os.listdir(document_path): 27. if file.endswith("xlsx") or file.endswith("xls"): 28. list1.append(file) 29. 30. for name in list1: 31. print(document_path+"/"+name) 32. if name[0:2]=="~$": 33. name=name[2:] 34. df=pd.read_excel(document_path+"/"+name) 35. 36. s=[] 37. for i in range(16): 38. for j in range(1,9,2): 39. s.append(df.values[i][j]) 40. 41. for i in range(len(s)): 42. sheet.write(cnt,i,s[i]) 43. cnt+=1 44. 45. savepath = 'E:/桌面/学习经历.xlsx' 46. book.save(savepath)
结果:

完整的代码我上传到了这里
(2条消息) 数据处理excel脚本.zip-统计分析文档类资源-CSDN文库
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

