免费代理IP网站:https://www.xicidaili.com/wt/1,我们爬取的IP就来源于该网站下的免费代理IP信息
requests模块,用于http形式请求访问网页
BeautifulSoup模块,用于解析获取到的网页内容
利用Python代码实现爬取可用代理IP,并将爬取到的IP地址载入到本地文件,方便后期使用
1、为防止网站可能存在的简单反爬机制,我们简单添加headers信息,尝试绕过反爬
2、为保证爬取到的代理IP的可用性,我们使用该代理IP尝试访问百度,若访问成功即写入本地文件
import requestsfrom bs4 import BeautifulSoupfrom threading import Thread
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}def get_ip():for page in range(1,100):resp = requests.get('https://www.xicidaili.com/wt/{}'.format(page),headers=headers)soup = BeautifulSoup(resp.text,'lxml')dates = soup.select('tr')for i in range(1,50):date = dates[i]date_detail = BeautifulSoup(str(date),'lxml')date_text = date_detail.select('td')IP = date_text[1].text
Port =date_text[2].text
Address = date_text[3].text
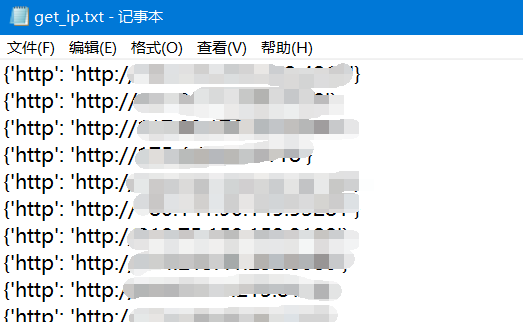
Protocol = date_text[5].textprint(f'{Protocol.lower()}://{IP}:{Port}\t{Address}')with open('get_ip.txt',mode ='a+') as file:file.write(f'{Protocol.lower()}://{IP}:{Port}\t{Address}\n')ip_judge = f'{Protocol.lower()}://{IP}:{Port}'proxy_list={ }proxy_list[Protocol.lower()] = ip_judge
resp_judge = requests.get(url = 'https://www.baidu.com',headers=headers,proxies=proxy_list)if resp_judge.status_code == 200:with open('get_ip.txt',mode ='a+') as file:file.write(f'{proxy_list}\n')else:print(f'This proxy is failed:{proxy_list}')get_ip()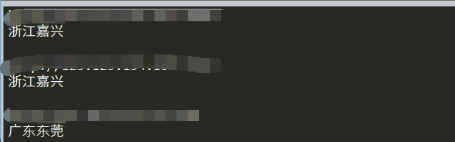
Copyright © 2023 leiyu.cn. All Rights Reserved. 磊宇云计算 版权所有 许可证编号:B1-20233142/B2-20230630 山东磊宇云计算有限公司 鲁ICP备2020045424号
磊宇云计算致力于以最 “绿色节能” 的方式,让每一位上云的客户成为全球绿色节能和降低碳排放的贡献者

